
struct와 class의 성능에 대해 자세히 알아보자
스위프트 코드 작성에 있어서, 좋은 성능을 고려하는 것은 당연한 개발자로써 당연한 것일 겁니다. 이번 글에서는 성능에 영향을 주는 것 중에서 다음 세가지를 중심적으로 이야기해보려고 합니다.
- Allocation: 인스턴스를 생성하면 Stack과 Heap 중 어느 곳에 할당 되는 지
- Reference Counting: 인스턴스를 통해 레퍼런스 카운트가 몇개가 발생하는지
- Method Dispatch: 인스턴스에서 메소드를 호출했을 때, 메소드 디스패치가 정적인지 동적인지
Allocation
Swift는 자동으로 메모리 할당과 해제를 처리합니다. 메모리 할당과 해제는 Stack 또는 Heap에서 처리됩니다. Stack과 heap의 특징은 다음과 같습니다.
Stack & Heap
Stack은 LIFO(Last In First Out)의 단순한 구조로 메모리 할당과 해제가 편리합니다. Stack은 Stack Pointer를 사용하여 할당・해제를 처리합니다. Stack은 단순한 구조를 가진만큼 시간복잡도는 O(1)으로 속도가 매우 빠릅니다.
Heap은 stack보다 더 복잡한 구조를 가지고 있습니다. Heap은 Stack보다 dynamic한 할당 방법을 사용하는데, Heap 영역에서 사용하지 않은 블록을 찾아서 메모리 할당을 처리합니다. 할당을 해제하기 위해서는 해당 메모리를 적절한 위치로 다시 삽입합니다. 여러 thread가 동시에 Heap에 메모리를 할당할 수 있기 때문에 locking 또는 기타 동기화 메커니즘을 사용하여 무결성을 보호해야합니다.
위 특징들을 살펴보면 알 수 있듯이, stack은 heap보다 비용이 더 적게 들어가며, 속도가 더 빠른 할당 방법입니다.
Value and Reference Semantics
그렇다면 메모리 할당 시 Stack, Heap에 저장되는 기준은 무엇일까요? 이는 semantics로 결정되는데, value semantics와 reference semantics으로 나뉘게 됩니다.
semantics는 어떤 타입, 기호가 내부적으로 어떤 의미인지를 뜻합니다.
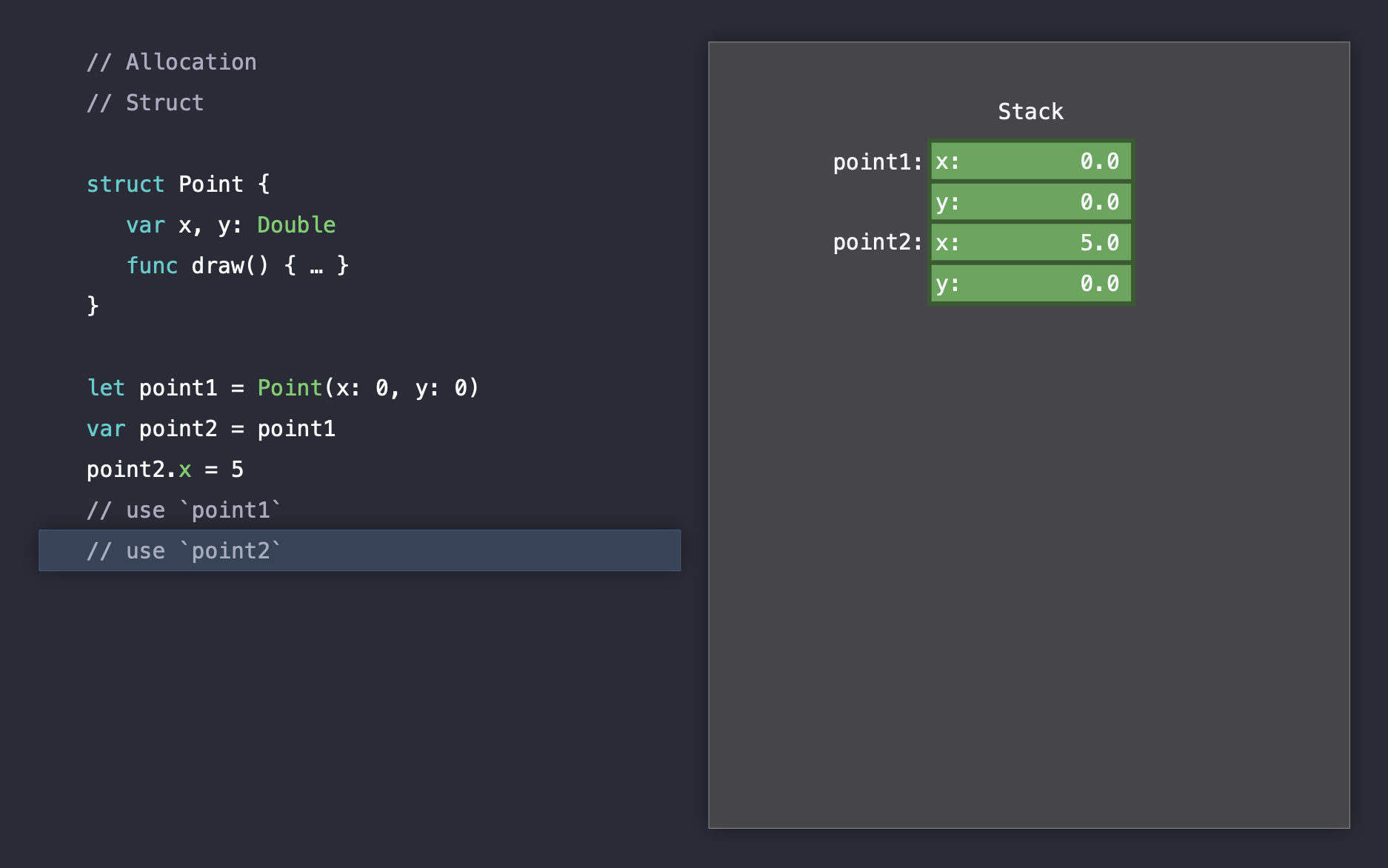
Value Semantics: Struct
Value semantics 타입들의 인스턴스는 stack에 할당됩니다. struct가 대표적인 value semantics를 따르고 있으며, struct 외에도 enum, tuple 그리고 기본 타입들이 있습니다.
Struct 인스턴스를 생성하여 다른 인스턴스에 할당하면, 전체 값은 그대로 복사가 됩니다. 복사된 인스턴스는 기존 인스턴스와 구분되어져 stack에 저장되기 때문에 내부 값을 변경해도 원래 값에 영향을 주지 않습니다. Heap을 사용하지 않기 때문에 reference counting도 사용하지 않습니다. Reference counting은 heap에서 발생하며 아래에서 더 자세하게 설명할 예정입니다.
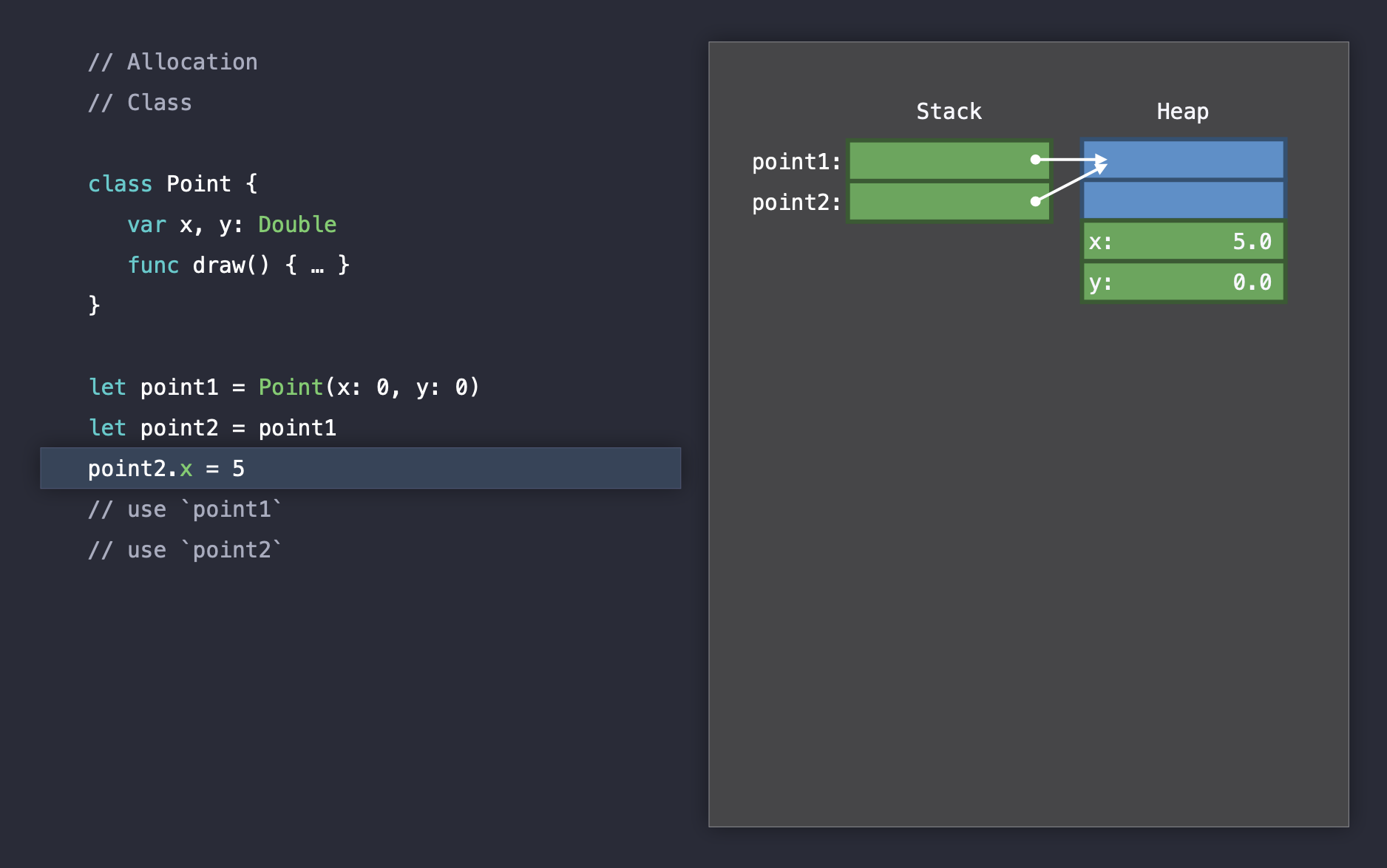
Reference Semantics: Class
Reference semantics는 stack에는 reference인 주소값을 할당하고, 실질적인 데이터는 heap에 할당합니다. 대표적으로 class가 있으며 function 또한 reference semantics입니다.
Class는 struct가 인스턴스 내부의 변수 개수에 맞추어 2words의 size로 stack에 할당되는 것과 달리 heap에 4words size로 할당됩니다. 이는 Swift가 우리 대신 클래스를 관리하기 위한 방법입니다. (파란색으로 표시된 박스)
word 하나에 하나의 변수를 저장할 수 있습니다.
Class는 reference semantics로 항상 하나의 identity라는 것을 유의해야합니다. Point 클래스의 인스턴스를 생성하고 복사하게 되면 stack에 있는 레퍼런스, 주소값이 복사되기 때문에 point1, point2는 모두 하나를 향해 같은 값을 가지게 됩니다. 그렇기 때문에 복사된 인스턴스를 수정하면 원래 인스턴스 데이터도 함께 변경되는 것처럼 보이게 됩니다.
여기까지 우리는 class를 사용하게 되면, Heap allocation을 사용하기 때문에 struct보다 더 많은 비용이 필요하다는 것을 알게 되었습니다. 그렇기 때문에 class의 특성이 필요하지 않으면 struct를 사용하는게 좋습니다.
다음 예시를 통해서 성능을 향상시킬 수 있는 방법을 살펴보도록 하겠습니다.
예시: Heap allocation 피하기
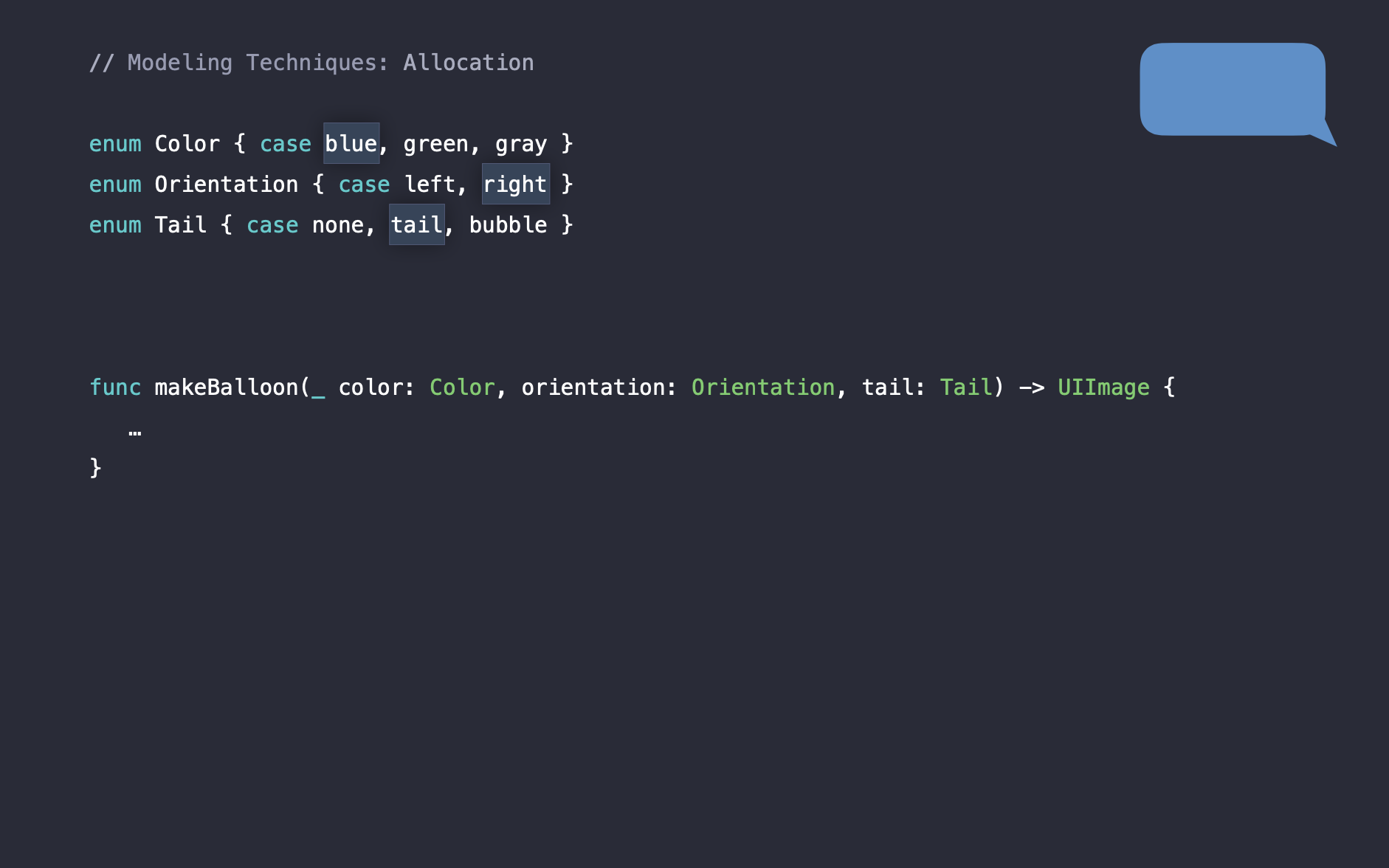
메세지 애플리케이션에서 사용하는 코드를 예시로 사용하겠습니다. 뷰 레이어에서 사용되는 코드이며, makeBalloon(_::)이라는 말풍선 이미지를 반환하는 함수입니다.
Color, Orientation, Tail enum을 사용해 각각의 case에 따라 말풍선 이미지를 반환하도록 구현되어있습니다.
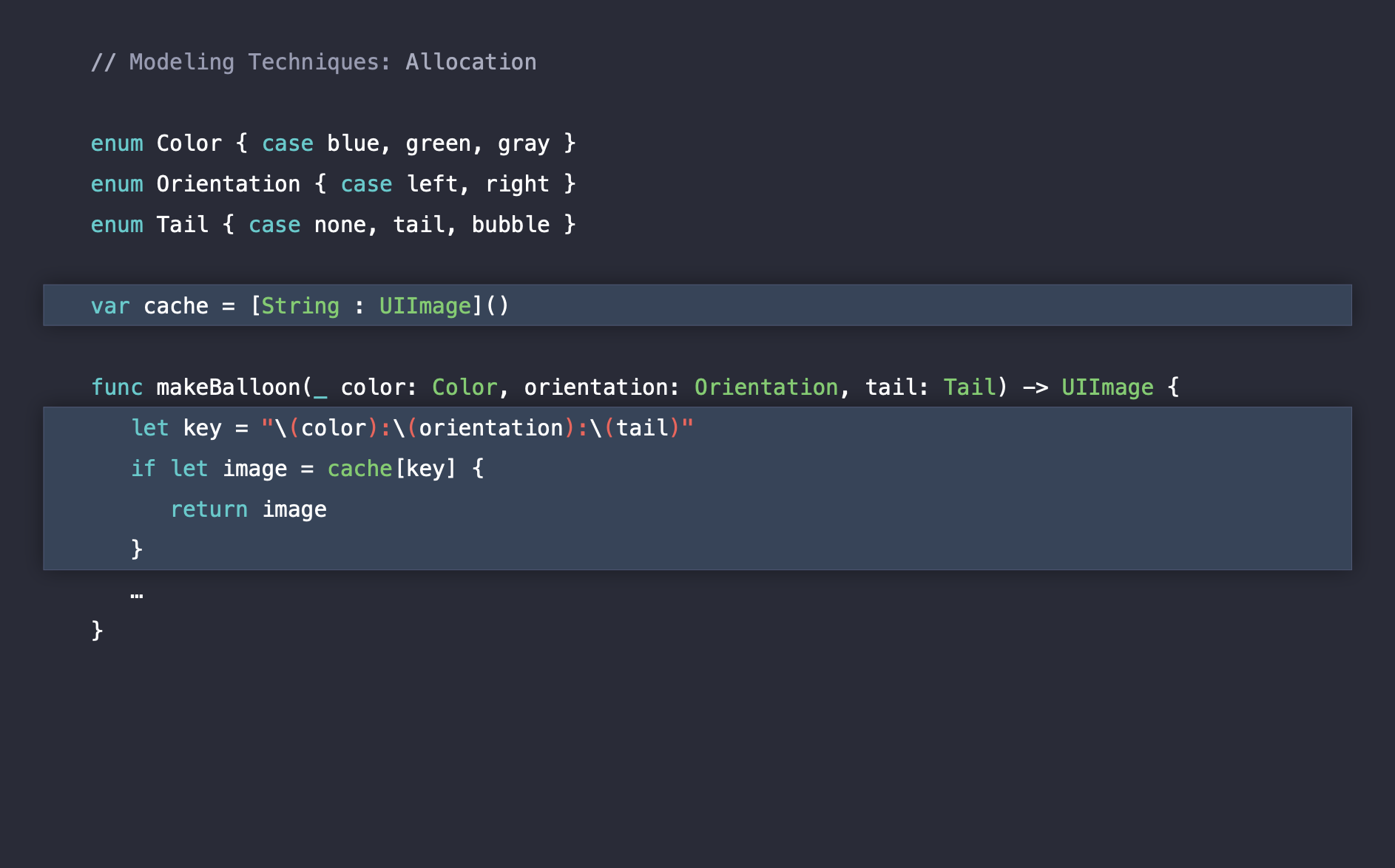
여기서 사용자가 스크롤을 할 때에 부드러운 뷰 처리를 위한 캐싱을 위한 Dictionary 타입의 cache를 만들어줍니다. 이렇게 되면 한번 만든 말풍선 이미지는 또 생성해서 만들 필요가 없이 cache dictionary를 통해 바로 가져올 수 있습니다. cache에서 캐싱을 위한 키역할을 하는 dictionary의 key는 Color, Orientation, Tail을 직렬화한 String 타입입니다.
let key = "\(color):\(orientation):\(tail)"
문제점 파악하기
먼저 성능과는 별개의 이야기로 key는 String 타입이기 때문에 다른 값이 들어갈 수 있는 위험이 있습니다. 또한 String은 value type이지만, heap에 character타입으로 문자들을 간접적으로 저장되기 때문에 String을 사용하게되면 heap allocation이 발생합니다. 그렇기 때문에 위와 같은 구조에서는 makeBalloon함수를 호출할 때마다, key로 인하여 heap allocation이 발생합니다.
이렇게 String은 Dictionary의 key로 사용하기에는 안전성이 떨어지고, Heap allocation을 발생시킵니다.
성능 올리기: Heap allocation 피하기
이를 위한 해결방법은 struct를 하나 더 만드는 것입니다. Attributes struct를 cache dictionary의 key 타입으로 사용하게 되면 stack allocation만 발생하기 때문에 비용과 시간을 감소시킬 수 있습니다. 또한 Attributes struct는 String이 사용되지 않고 정해진 enum 값들의 조합만으로 생성되기 때문에 dictionary의 key로 사용하기에 더욱 안전한 방법입니다.
struct Attributes: Hashable {
var color: Color
var orientation: Orientation
var tail: Tail
}
Hashable protocol은 스위프트에서 커스텀 객체를 collection에 사용하기 위해 필요한 인터페이스입니다. Dictionary의 key값으로 사용하기 위해 채택하였습니다.
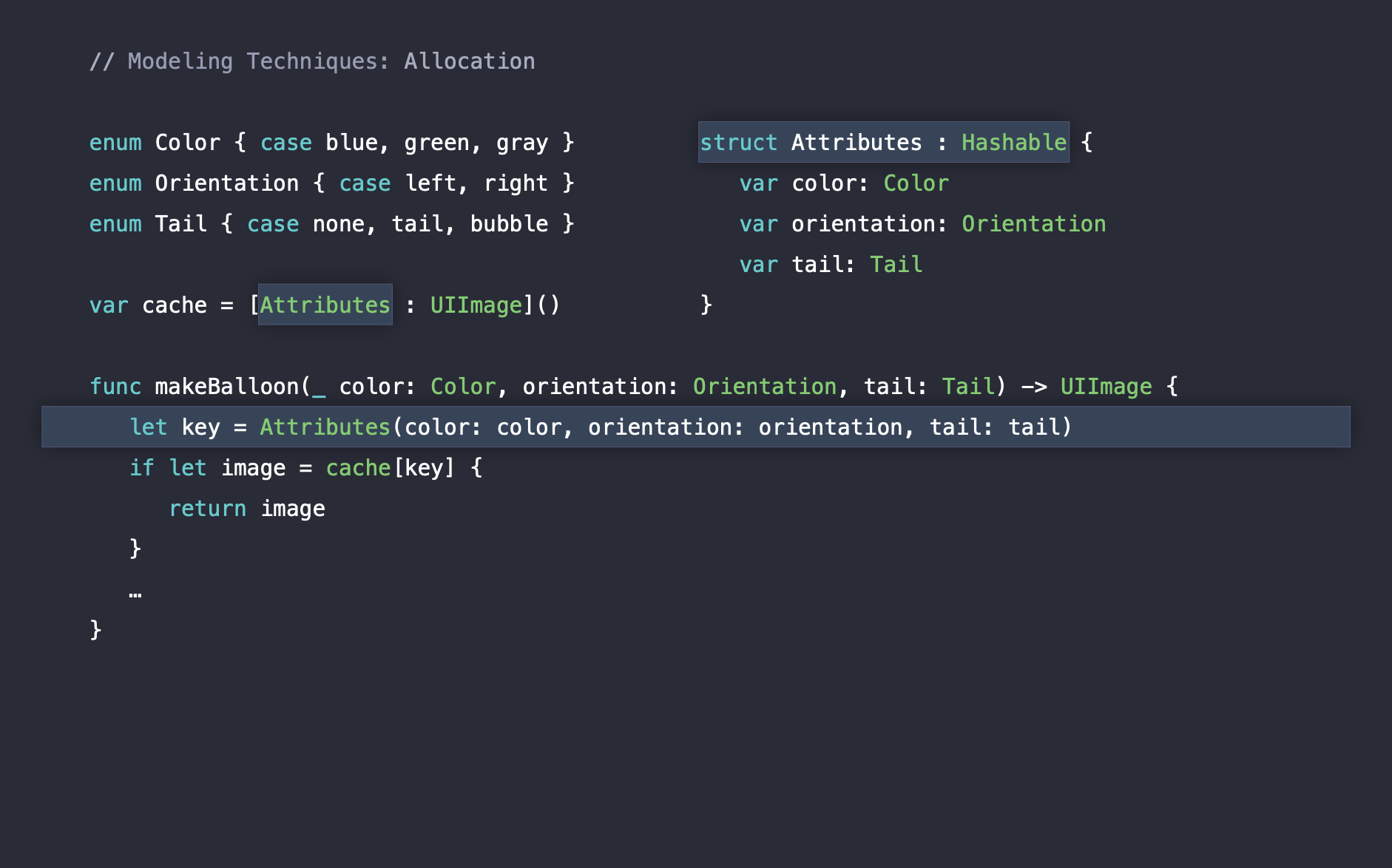
위와 같이 코드를 수정하게 되면, 이미 cache된 말풍선 이미지를 불러오는 과정에서는 할당이 발생하지 않습니다.
Reference Counting
위에서 heap allocation에 관하여 언급했을 때 reference counting도 잠깐 언급했었습니다. Reference counting 말 그대로 참조된 인스턴스의 개수를 세는 것입니다. Heap 영역에 할당하는 것 자체가 레퍼런스를 사용하기 때문에 reference counting이 발생합니다.
Swift의 Heap 영역의 메모리 해제
Reference Counting을 사용하는 이유에는 메모리 해제가 있습니다. Swift는 reference counting을 통해서 할당 해제 여부를 결정하고, reference count는 퍼포먼스에도 영향을 줍니다.
Swift는 힙에 있는 모든 인스턴스의 레퍼런스 카운트를 가지고 있습니다. 또한 이 레퍼런스 카운트를 인스턴스가 직접 가지고 있게 합니다. 이러한 레퍼런스 카운트는 레퍼런스가 추가되거나 제거될 때, 레퍼런스 카운트는 증가되거나 감소됩니다. 레퍼런스 카운트가 0이되면 Swift는 해당 인스턴스를 아무도 사용하지 않는다고 간주하여 메모리에서 해제하기에 안전하다고 판단합니다.
Reference Counting in Class
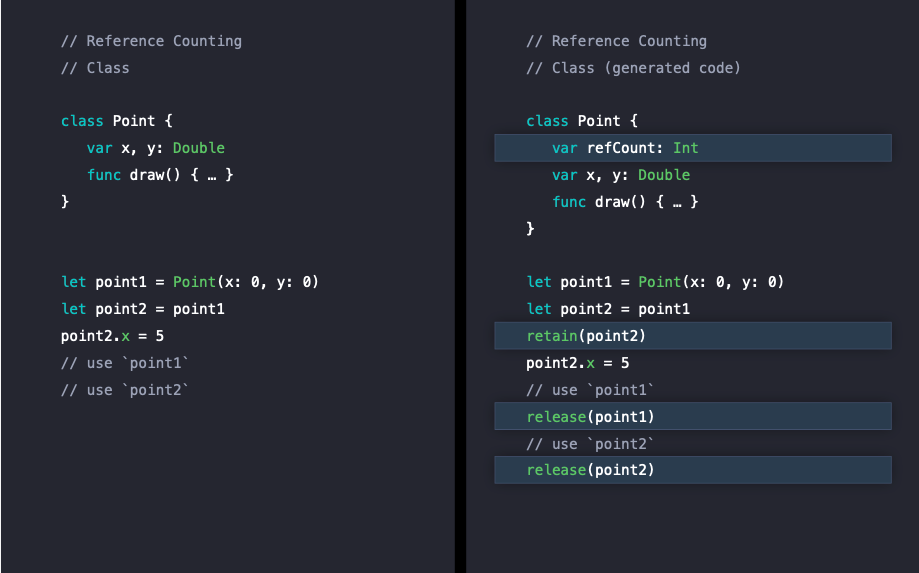
먼저 클래스에서 생기는 reference counting 과정을 살펴보도록 하겠습니다.
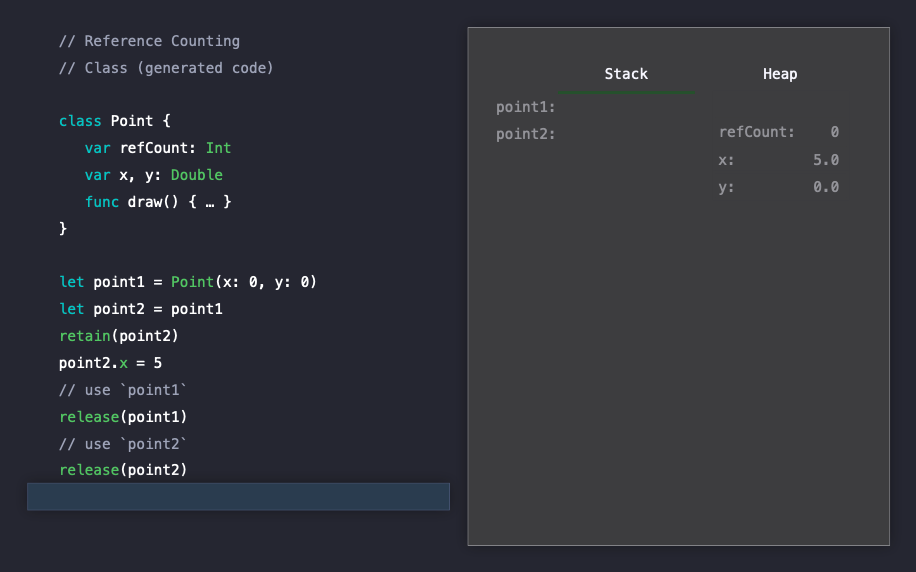
오른쪽 코드는 왼쪽 Point 클래스에서 reference counting 과정을 구체적으로 살펴보기 의사코드입니다.
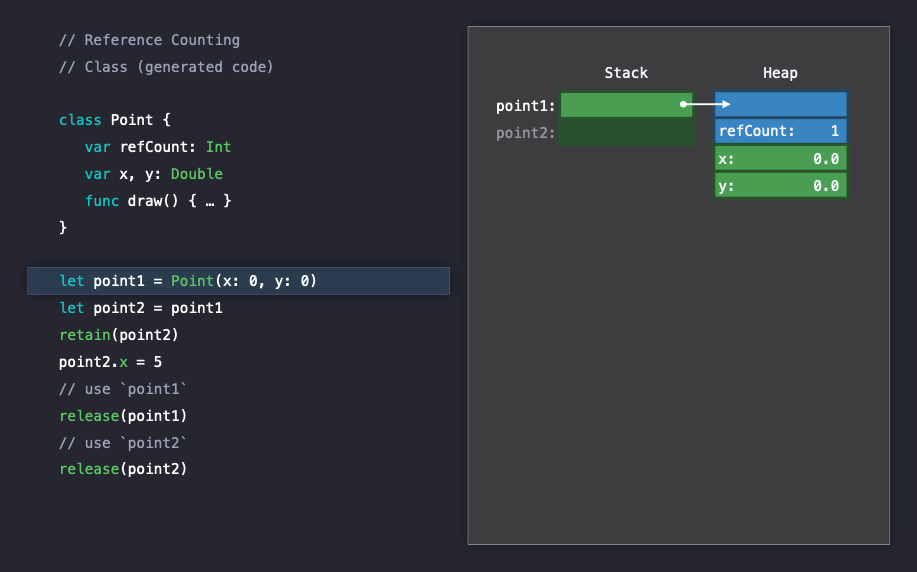
Allocation 부분에서 설명했듯이 Point는 클래스로 작성되어있기 때문에 인스턴스를 생성하게 되면, Point 클래스의 데이터는 heap에 할당되게 됩니다. 그리고 stack에는 이에 대한 레퍼런스가 저장되며 reference counting을 증가시킵니다.
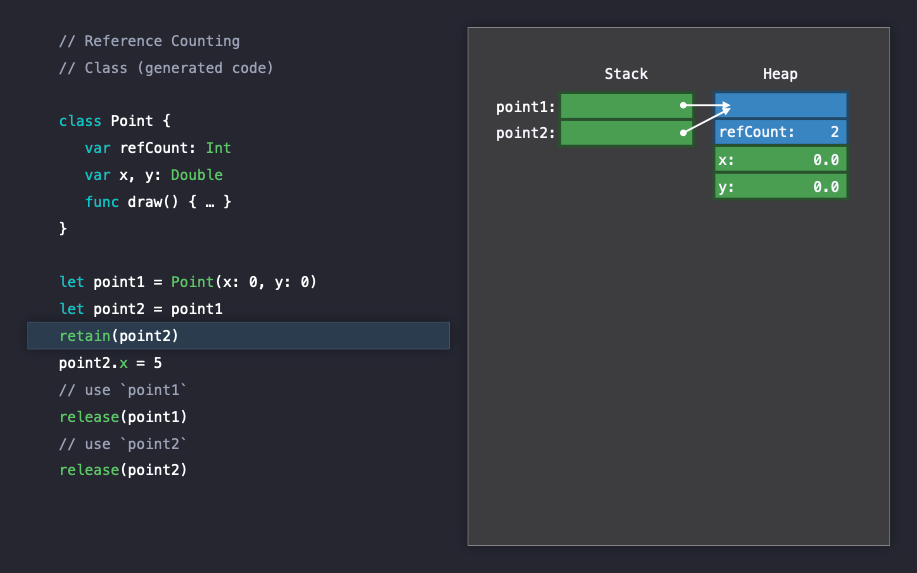
point1 인스턴스를 다른 인스턴스에 복사하게 되면, Heap에 있는 기존 인스턴스에 대해 레퍼런스가 추가적으로 발생하게 되며 reference counting이 발생하게되고 카운트는 1이 증가하게 됩니다.
retain(point2)
여기서 point2 인스턴스의 프로퍼티를 수정하게 되면, Reference semantics를 따르는 class이기 때문에 두 인스턴스가 참조하고 있는 heap 영역의 인스턴스의 프로퍼티가 수정되게 되며, point1, point2가 모두 수정되는 것 처럼 보이게됩니다.
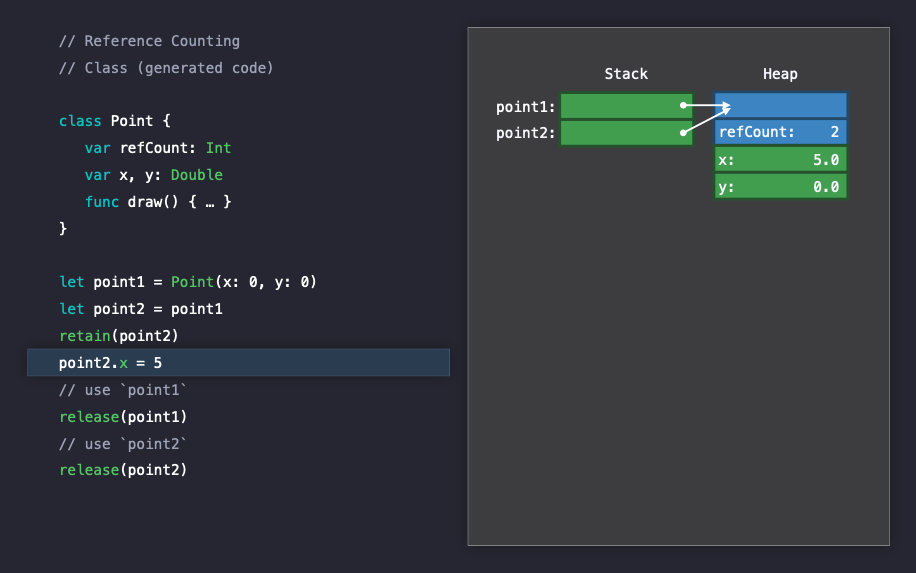
이제 모든 인스턴스의 사용이 끝나고 두 인스턴스를 차례로 release 하게 되면, reference count를 나타내는 refCount는 0이 되게 됩니다. 이 때 release를 통해서 Swift는레퍼런스 카운트 감소를 원자적(atomically)으로 처리하게 됩니다.
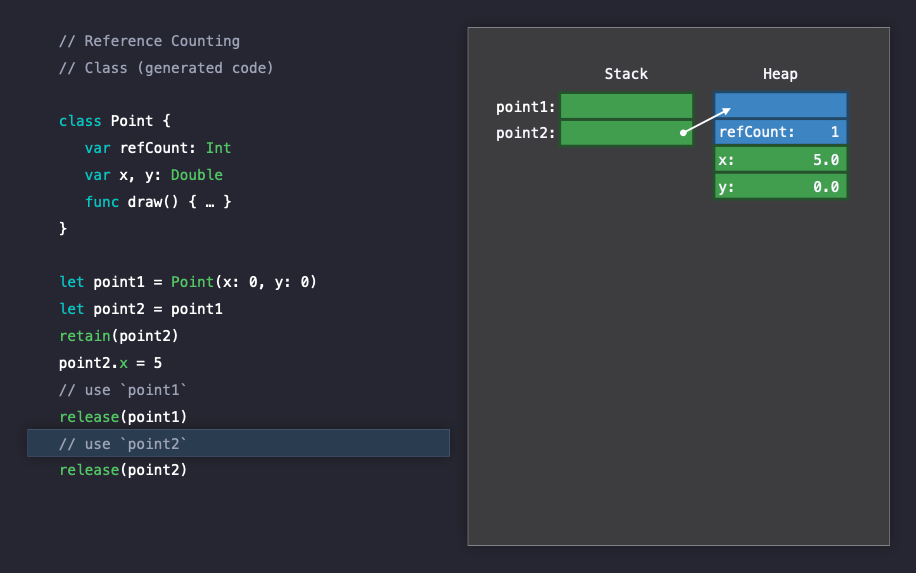
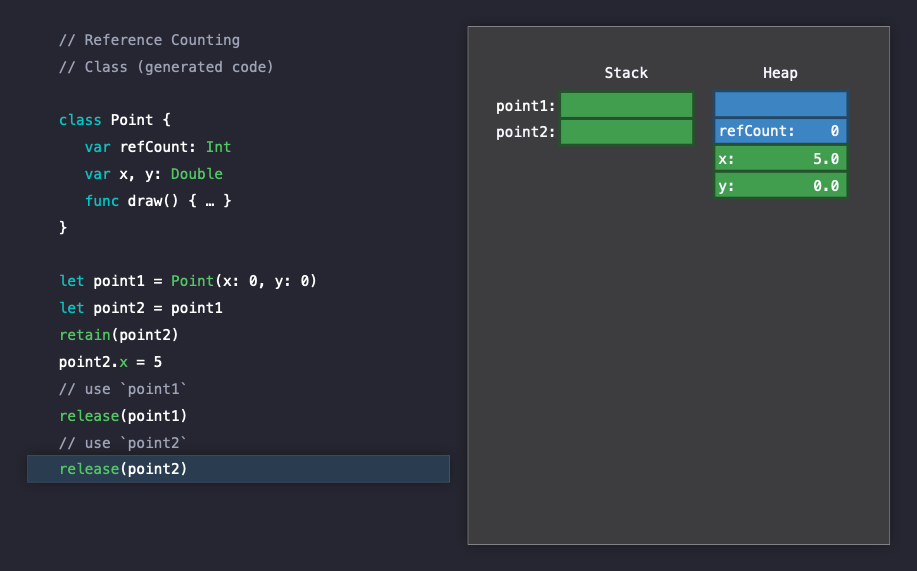
이제 Swift는 해제해도 안전하다고 판단하고, heap을 lock하고 메모리 블럭을 반환합니다.
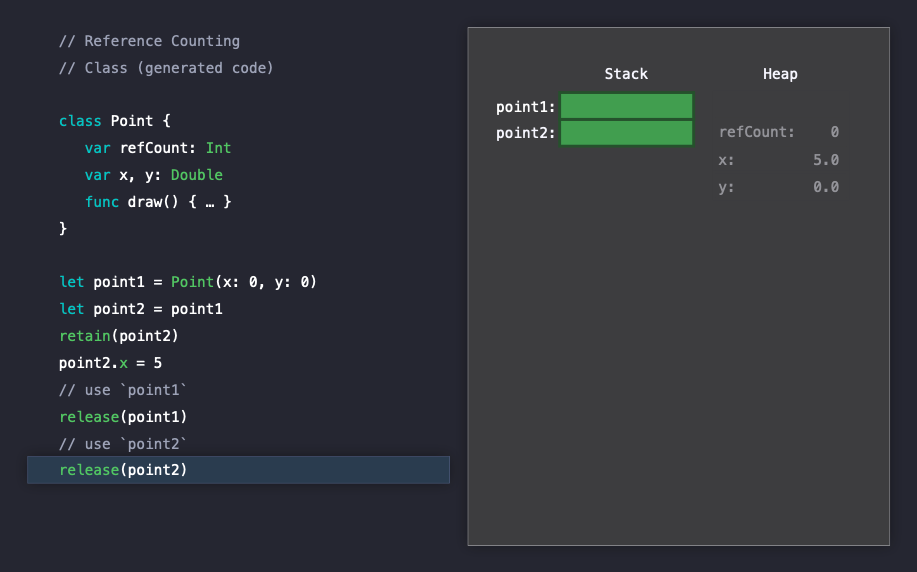
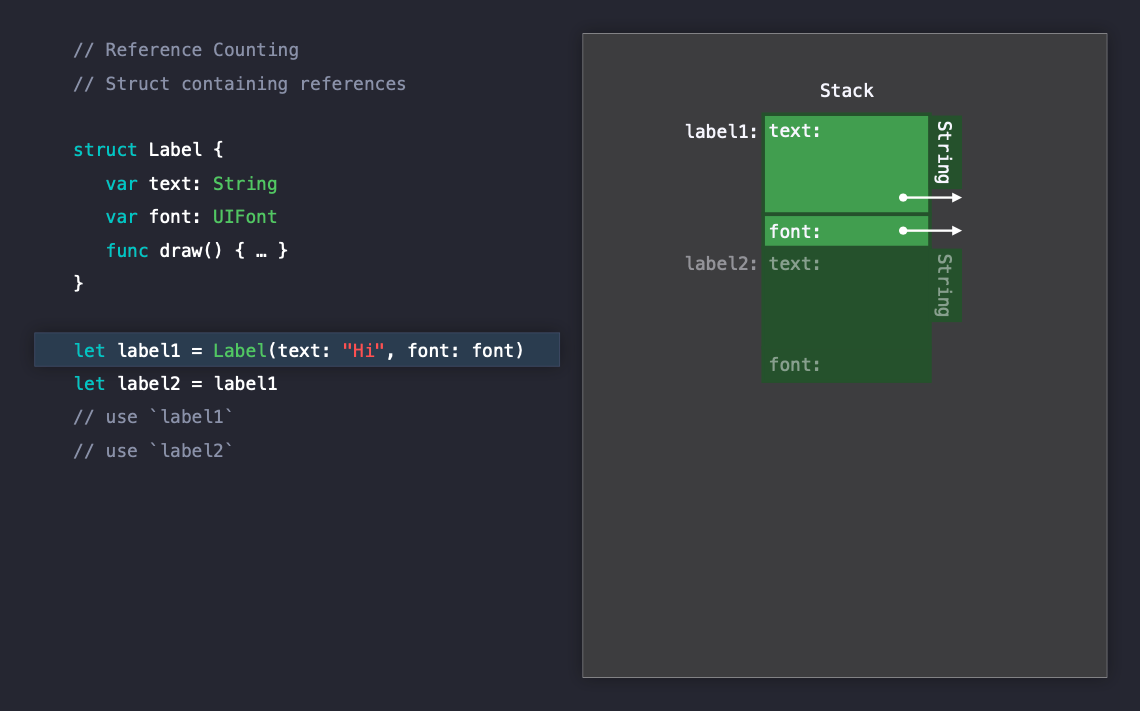
Reference Counting in Struct
Heap 할당이 일어나지 않는 struct에서는 reference counting이 발생하지 않는다고 생각하기 쉽습니다. 하지만, Struct가 reference semantics를 따르는 타입을 프로퍼티로 가지게 된다면 reference counting은 발생합니다.
다음 Label 구조체는 다음과 같이 String 타입의 text와 UIFont 타입의 font를 프로퍼티로 가지고 있습니다.
Struct Label {
var text: String
var font: UIFont
func draw() { ... }
}
String은 할당 파트에서도 언급했듯이 character들을 힙에 저장하기 때문에 레퍼런스 카운트가 필요합니다. UIFont 또한 클래스로 만들어진 객체이기 때문에 레퍼런스 카운트가 필요합니다. 그러므로 Label 구조체의 인스턴스를 생성하게 되면, 아래 이미지와 같이 두개의 레퍼런스가 발생하게 되며 reference counting이 발생하게 됩니다.
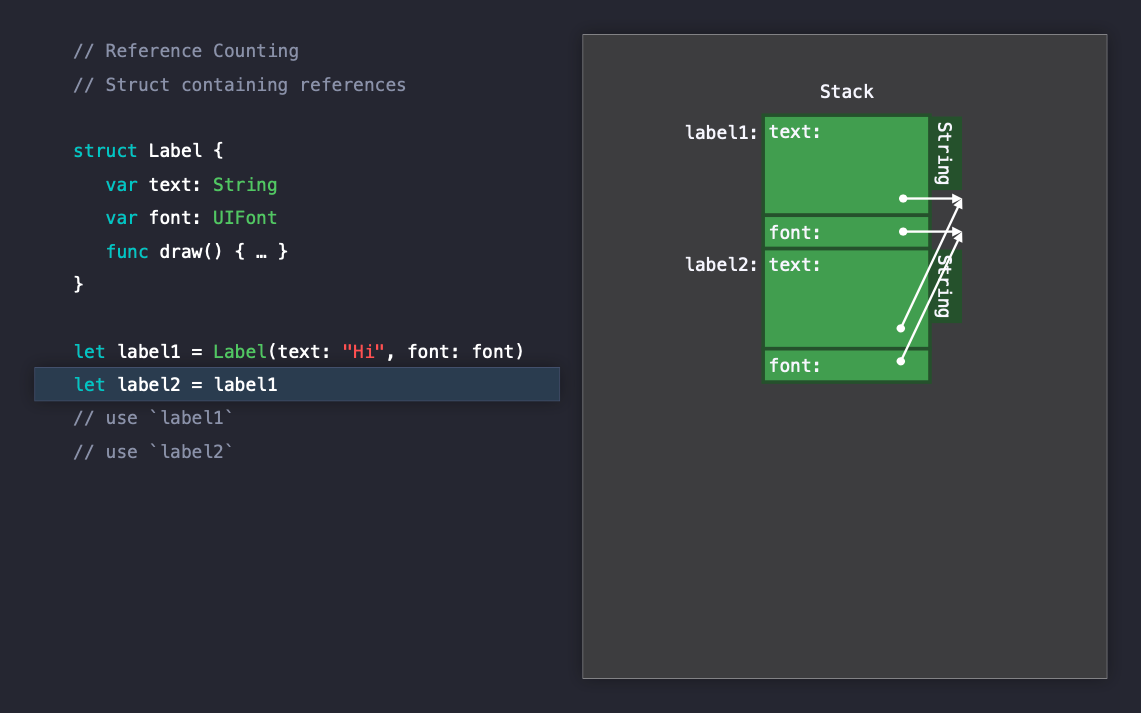
이러한 Label 구조체를 복사하게 되면 레퍼런스 text, font의 레퍼런스 하나씩이 복사되어 총 카운트가 2개가 추가됩니다.
인스턴스들을 모두 사용 후에 레퍼런스들은 모두 release() 해줘야 합니다. 두개의 구조체 인스턴스를 사용했는데, 레퍼런스로 인해서 4번을 release하는 비용을 지불하게 됩니다.
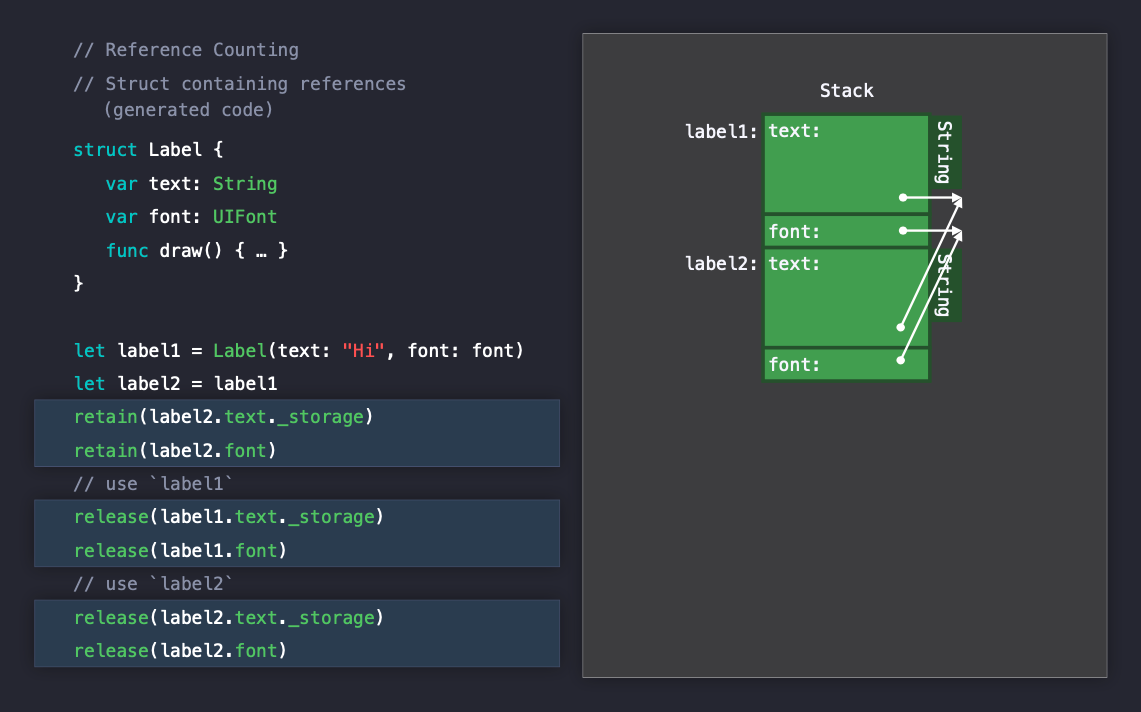
정리하자면, 클래스는 힙에 할당되기 때문에 Swift는 heap allocation 라이프타임을 관리해야합니다, 이것은 레퍼런스 카운팅으로 처리하게 됩니다.
반면 구조체는 기본적으로 레퍼런스를 사용하지 않지만, 구조체가 레퍼런스를 가지게 되면 reference counting으로 오버헤드(overhead)를 처리하는 비용이 들게 됩니다.
오버헤드(overhead)는 어떤 처리를 하기 위해 들어가는 간접적인 처리 시간·메모리 등을 말합니다.
여기서 구조체의 reference counting 오버헤드는 구조체에 있는 레퍼런스 개수에 비례하게됩니다. 그래서 만약 구조체에서 하나보다 더 많은 레퍼런스를 가지게 된다면, reference counting 오버헤드가 클래스보다 더 많이 발생하게 됩니다. 😦
예시: References in Struct
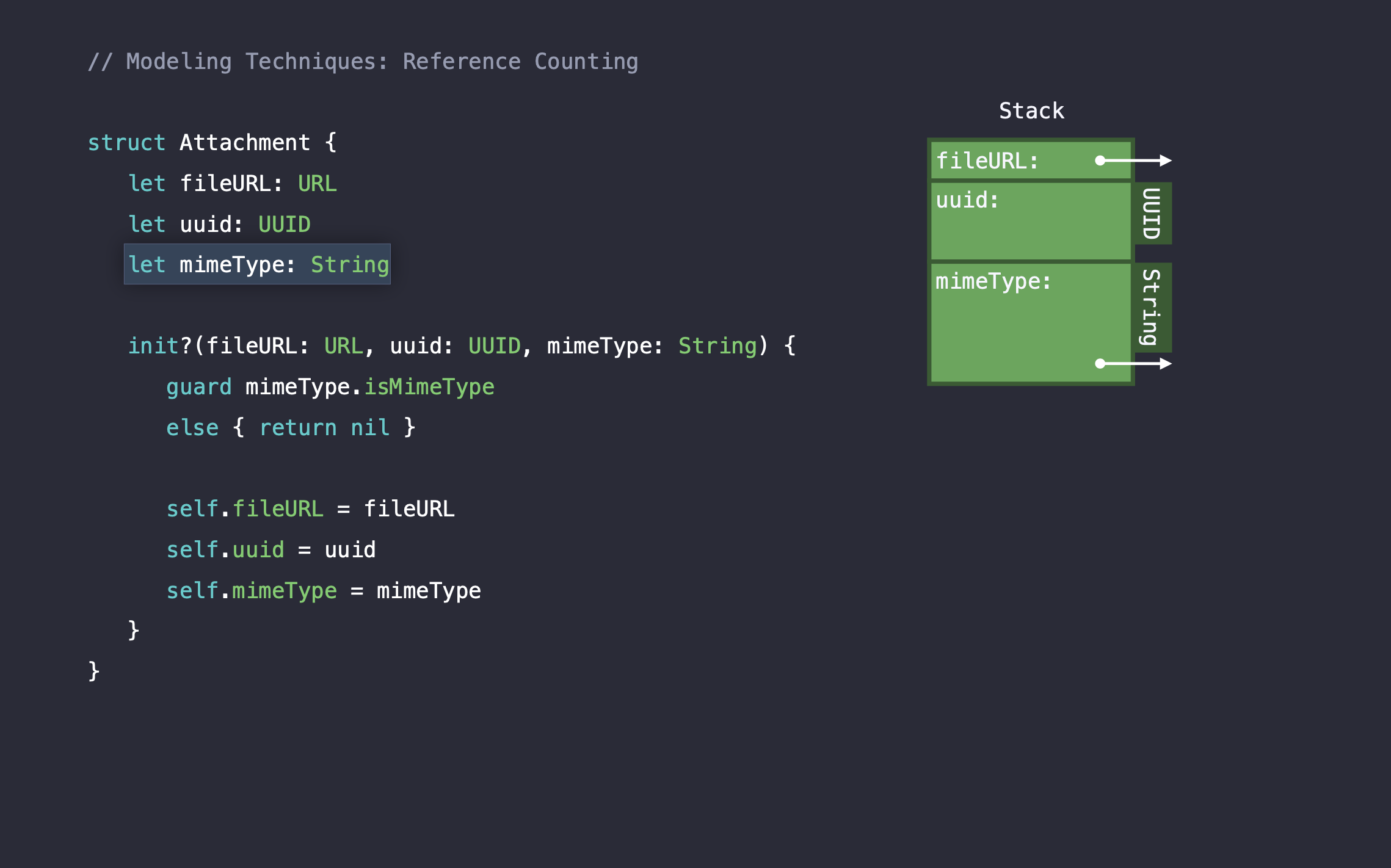
메세지 앱에서 첨부파일을 보내는 코드를 작성한다고 해봅시다. 첨부파일을 위한 모델 객체인 구조체 Attachment는 다음과 같이 작성되어 있습니다. Attachment에는 디스크에서 데이터의 파일 경로를 나타내는 URL 타입의 fileURL, 고유 아이디로 사용할 String 타입의 uuid, 파일 타입(JPG, PNG, GIF 등)을 나타내는 String타입의 mimeType이 있습니다.
initializer에서는 특정 mimeType만 처리할 수 있도록 guard문을 사용했습니다.
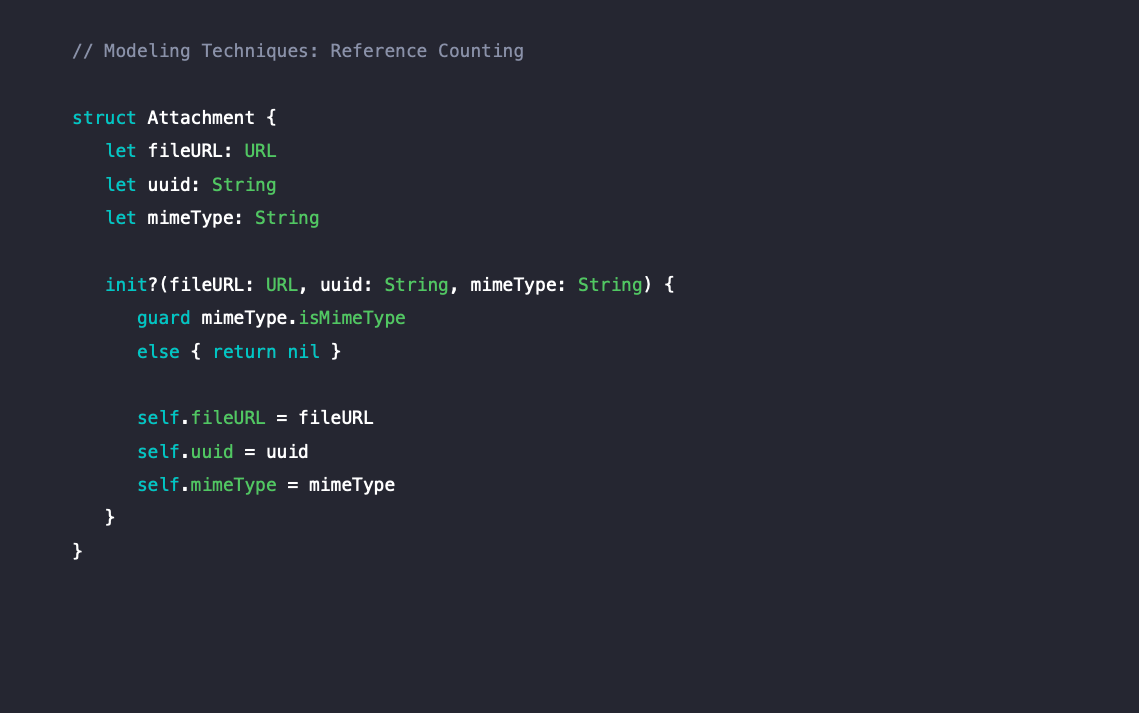
문제점 파악하기
URL은 구조체이지만, String을 생성자로 받아서 만들어지기 때문에 레퍼런스가 발생하고, 나머지 프로퍼티는 String이므로 모두 레퍼런스가 발생합니다. 3개의 프로퍼티 모두 reference counting 오버헤드를 발생시킵니다. 따라서 Attachment 구조체의 인스턴스의 메모리는 다음과 같이 나타납니다.
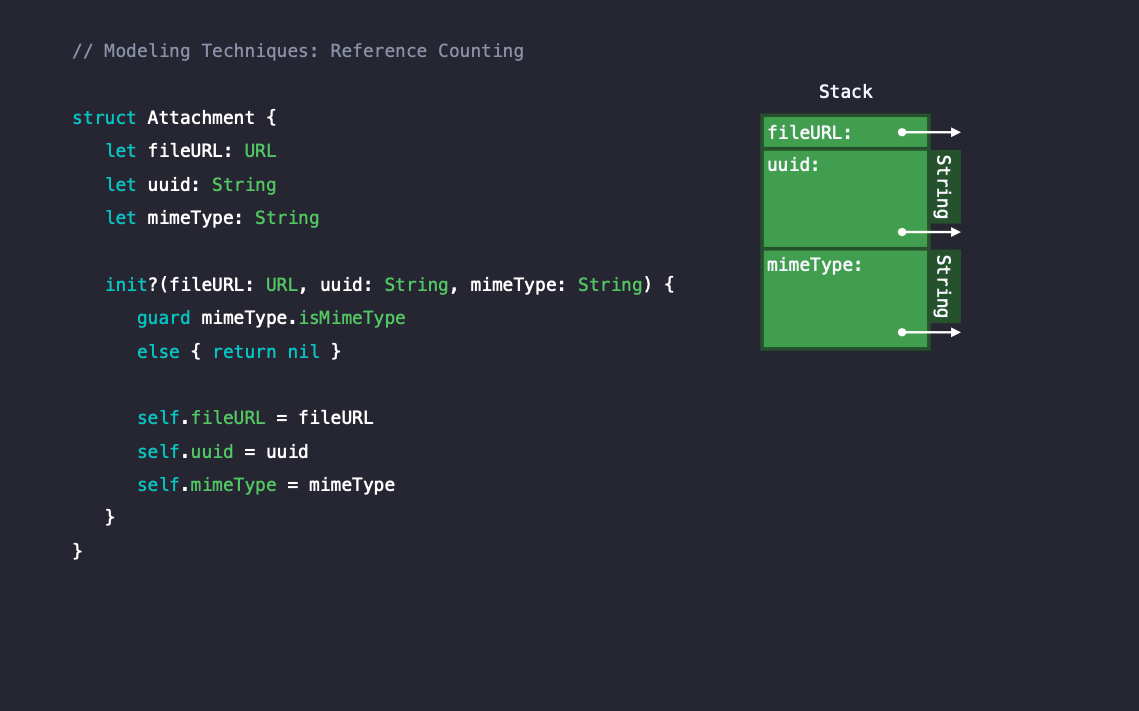
Attachment 인스턴스 하나를 생성하는 것만으로도 3개의 레퍼런스가 발생하기 때문에 오버헤드가 많이 발생하게됩니다.
성능 올리기: Reference Counting Overhead 최소한으로 줄이기
URL은 대체할 수 있는 타입이 없기 때문에 그대로 사용해야 합니다. Struct에서 하나의 레퍼런스는 성능에 큰 영향을 끼치지 않기 때문에 괜찮습니다.
uuid 프로퍼티는 UUID라는 struct 타입으로 대체할 수 있습니다. 공식문서에 나와있는 UUID 타입은 다음과 같습니다.
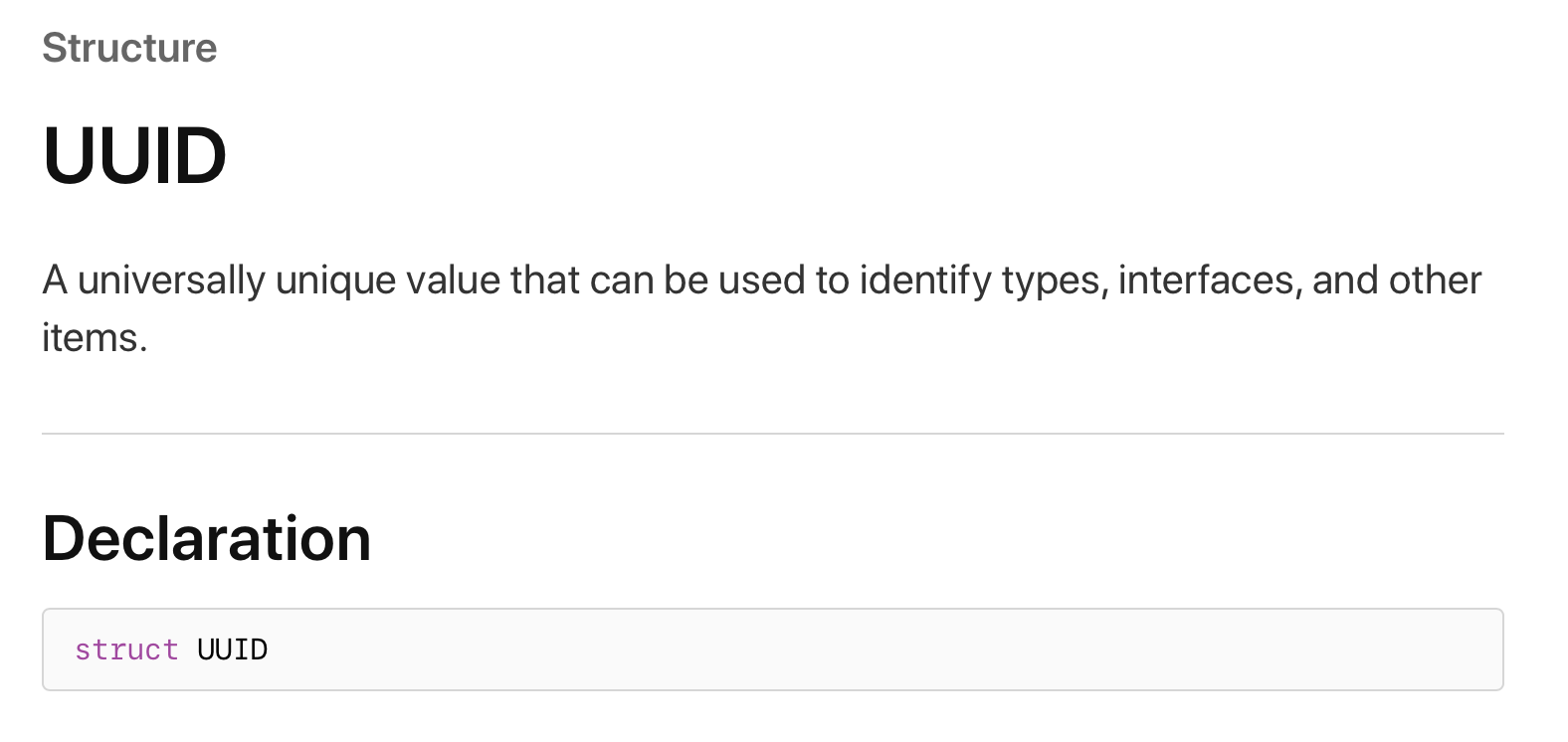
uuid의 타입을 UUID로 변경하게 되면 Attachment 구조체에 레퍼런스가 하나 줄어들게 됩니다.
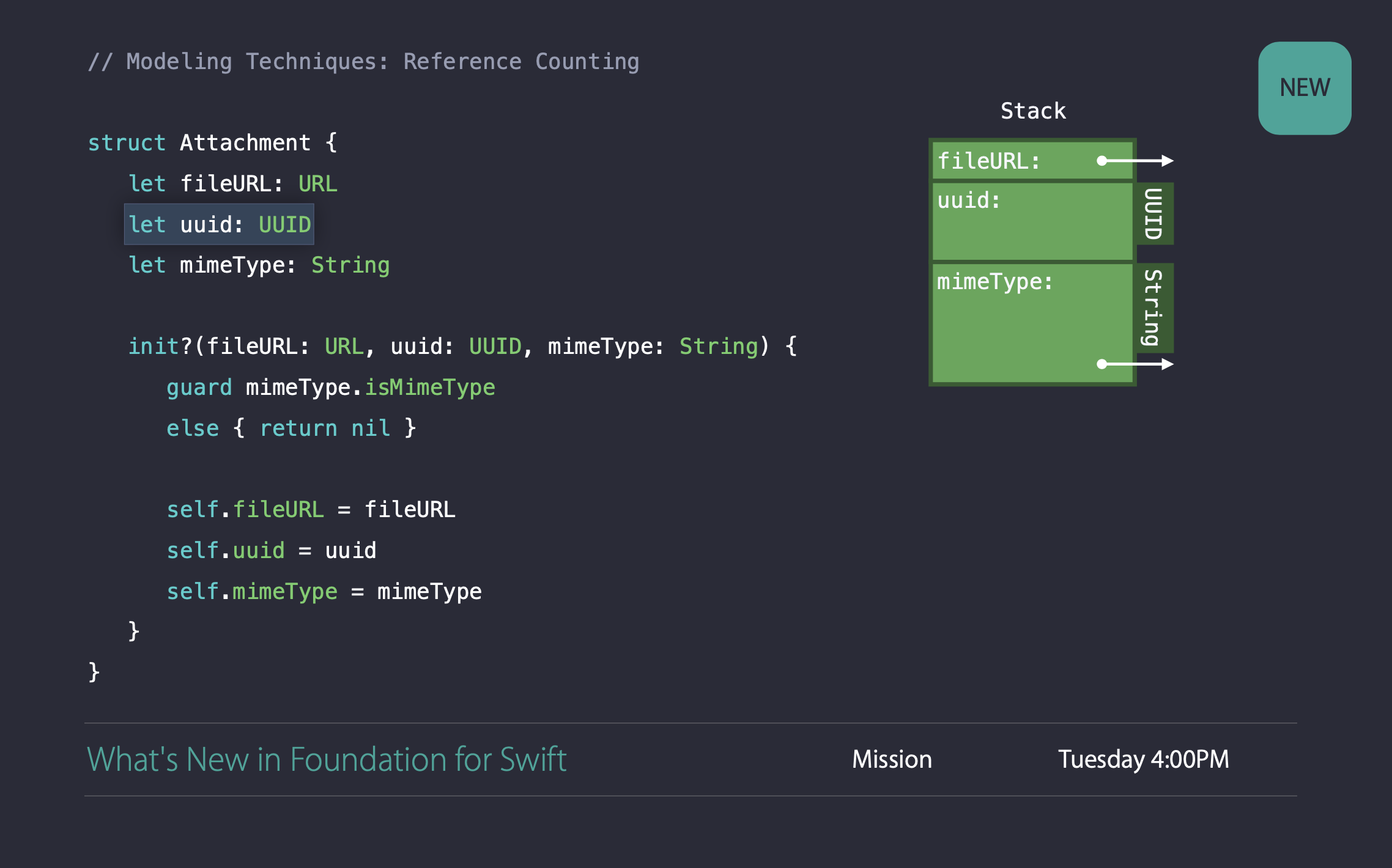
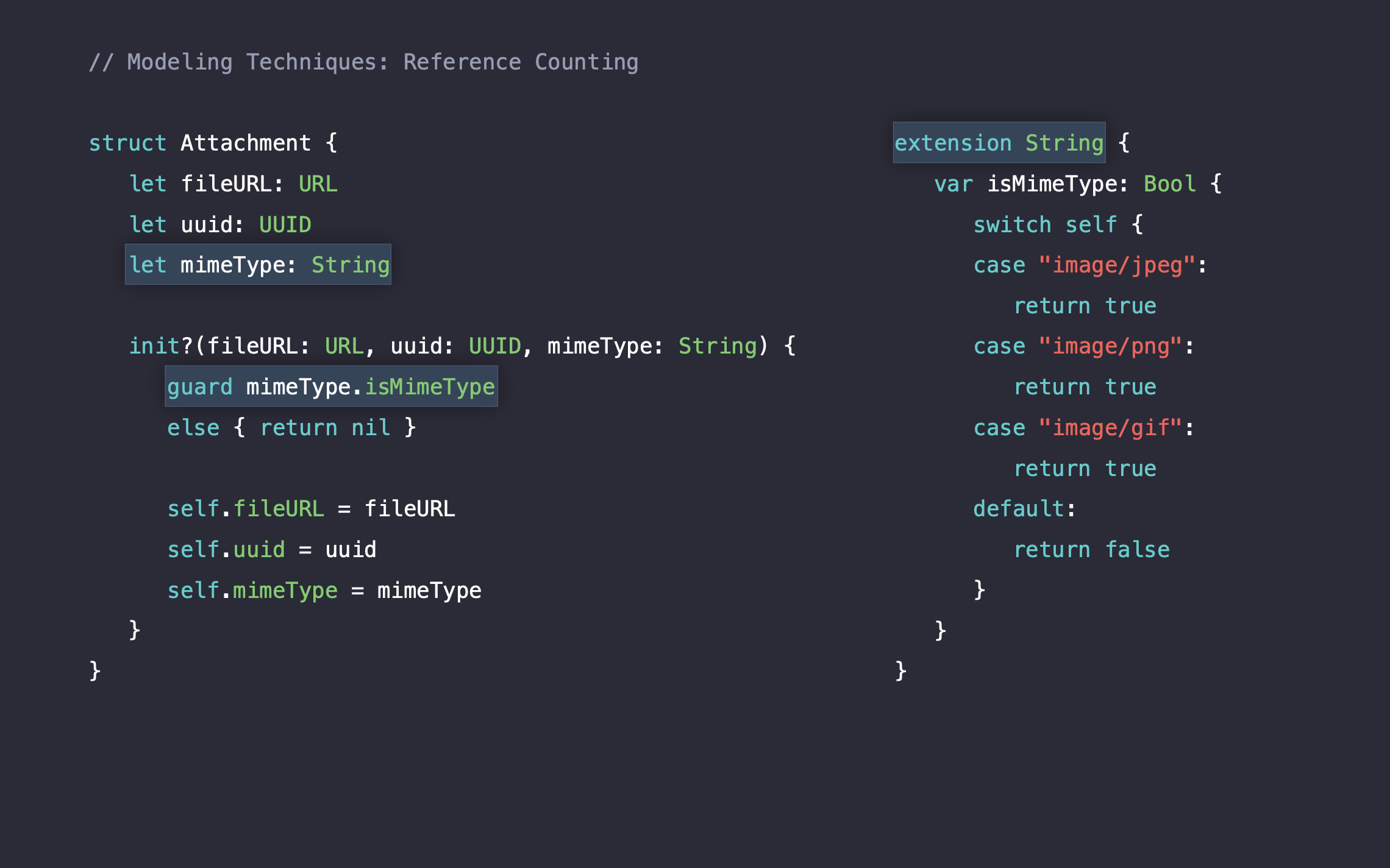
마지막 프로퍼티인 mimeType는 기존 String 타입에서 extension을 사용하여 guard문을 처리하고 있었습니다.
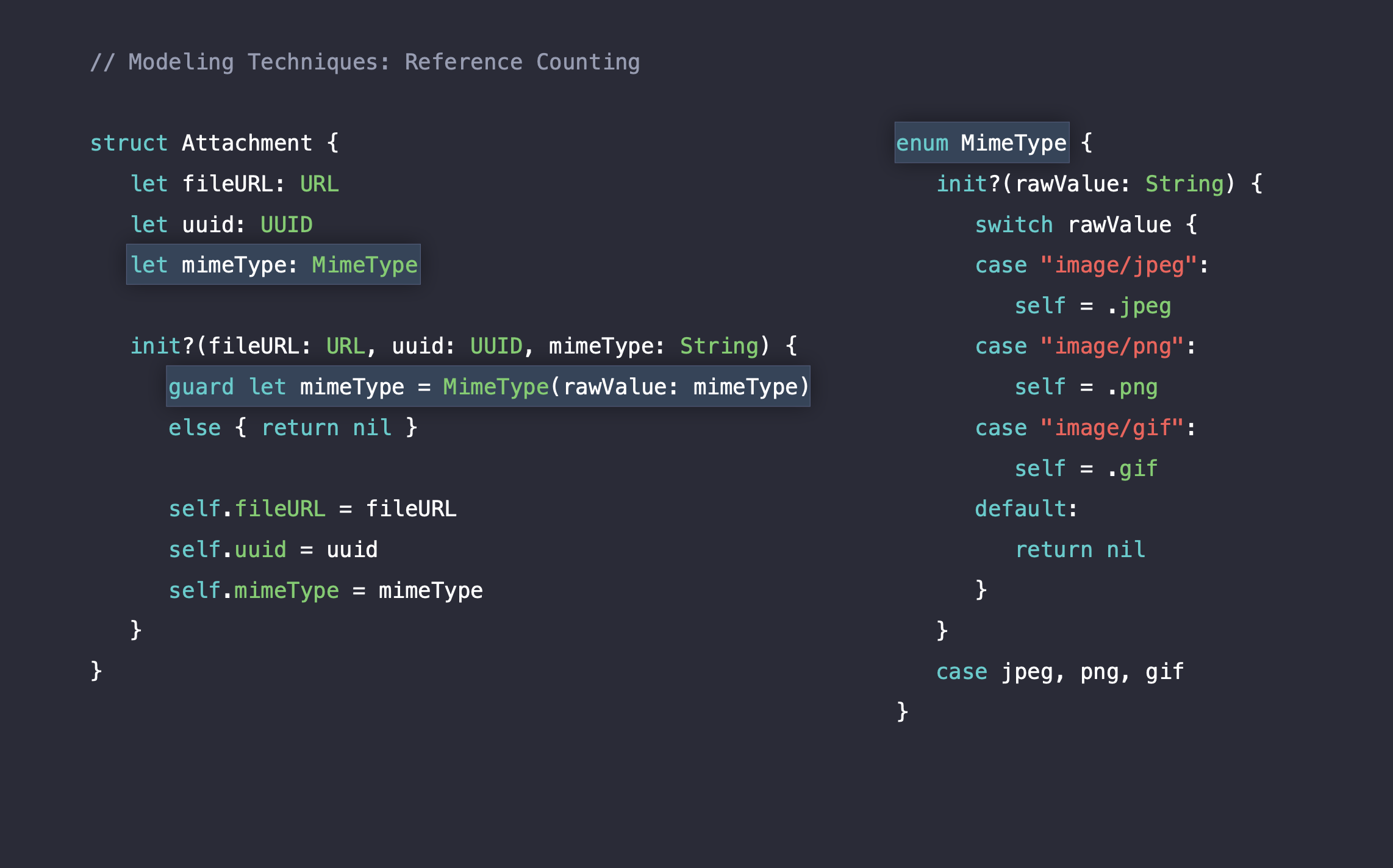
mimeType은 value type인 enum 타입으로 대체할 수 있습니다.
mimeType까지 모두 레퍼런스를 제거 해주고 난 후에 메모리는 다음과 같아집니다.
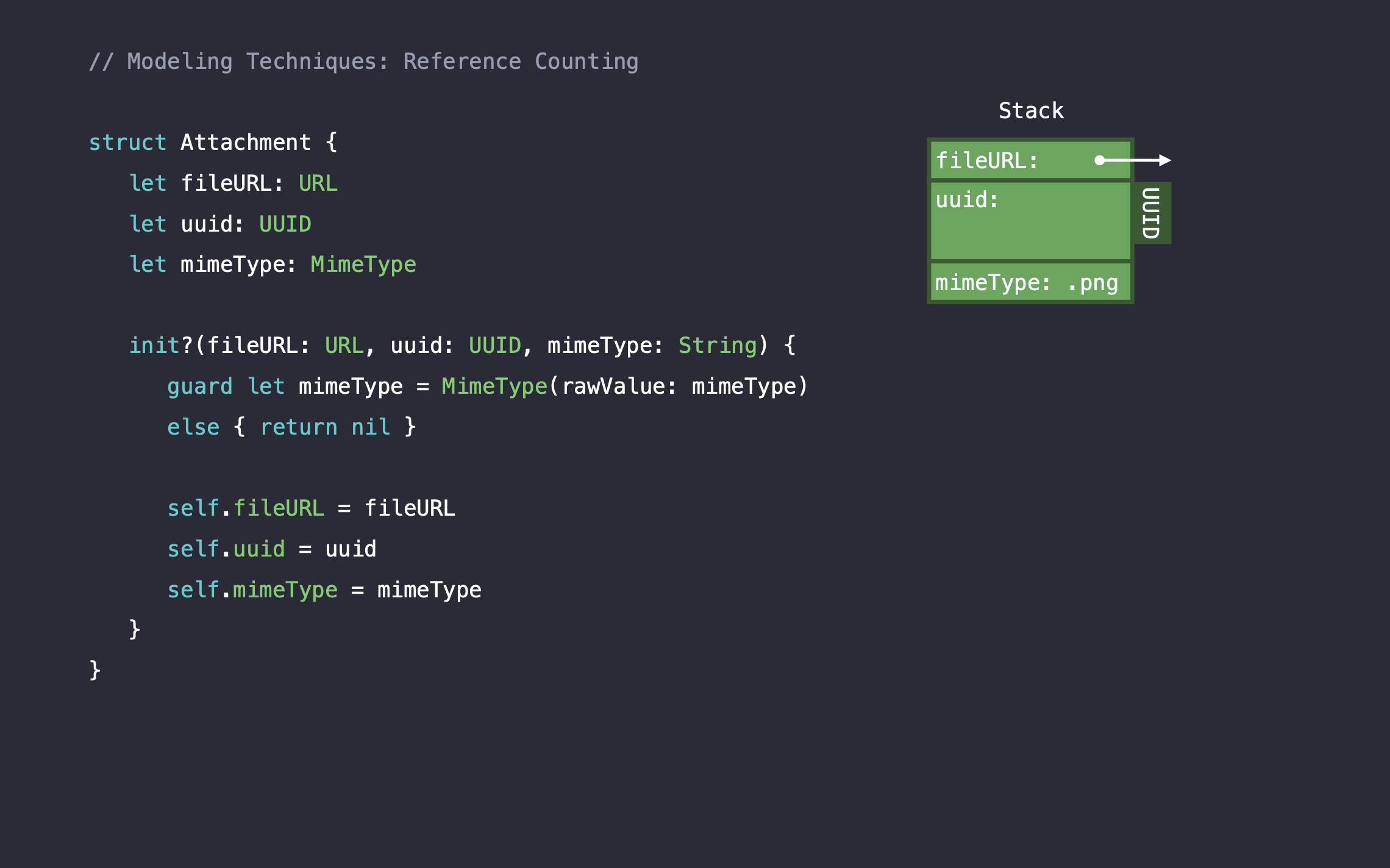
Struct에서 여러개의 레퍼런스를 사용하는 프로퍼티를 사용하게 되면, 클래스보다 성능이 더 안좋아질 수 있습니다. 이러한 방법으로 프로퍼티들의 타입을 변경하시면, 레퍼런스 카운팅 오버헤드를 줄일 수 있습니다.
Method Dispatch
Method dispatch는 프로그램이 어떤 메소드를 호출할 것인지 결정하여 그 메소드를 호출하는 과정을 뜻합니다. 어떤 메소드인지 결정되는 시점에 따라 static method dispatch 와 dynamic method dispatch로 나뉘게 됩니다.
Static Method Dispatch
Static method dispatch는 컴파일 시점에 컴파일러가 메소드의 실제 코드 위치를 파악할 수 있어 런타임에 찾는 과정 없이 바로 해당 코드를 실행하는 것을 의미합니다.
구현된 코드들이 어디서 실행되는지 알 수 있기 때문에 메소드 인라이닝과 같은 코드 최적화를 적극적으로 시행합니다.
메소드 인라이닝(Method Inlining)은 메소드를 호출 할 때 해당 메소드로 이동하지 않고 메소드의 결과값을 바로 반환하여 성능을 향상 시키는 것입니다.
Dynamic Method Dispatch
Dynamic method dispatch는 컴파일 타임에 어떤 메소드를 호출하는지 판단할 수 없어, 런타임에 table에 구현을 참조하여 해당 메소드에 대한 정보를 가져와서 코드를 실행시키는 것을 의미합니다.
사실 dynamic dispatch는 static dispatch보다 그렇게 많은 비용을 필요로 하지는 않습니다. 레퍼런스 카운팅, 힙 할당과 같은 쓰레드 동기 오버헤드가 없습니다.
하지만 컴파일러는 static dispatch에서는 최적화 작업이 가능하지만, Dynamic dispatch에서는 컴파일러가 추론할 수 없습니다.
Method Dispatch in Struct
먼저 구조체에서 method dispatch는 어떻게 처리되는지 보겠습니다. Point 구조체는 draw라는 메소드를 가지고 있으며, drawAPoint() 메소드는 Point 타입을 파라미터로 받아서 인스턴스의 draw() 메소드를 호출합니다. 그리고 (0,0) Point 인스턴스를 생성해 drawAPoint() 메소드에게 넘겨줬습니다.
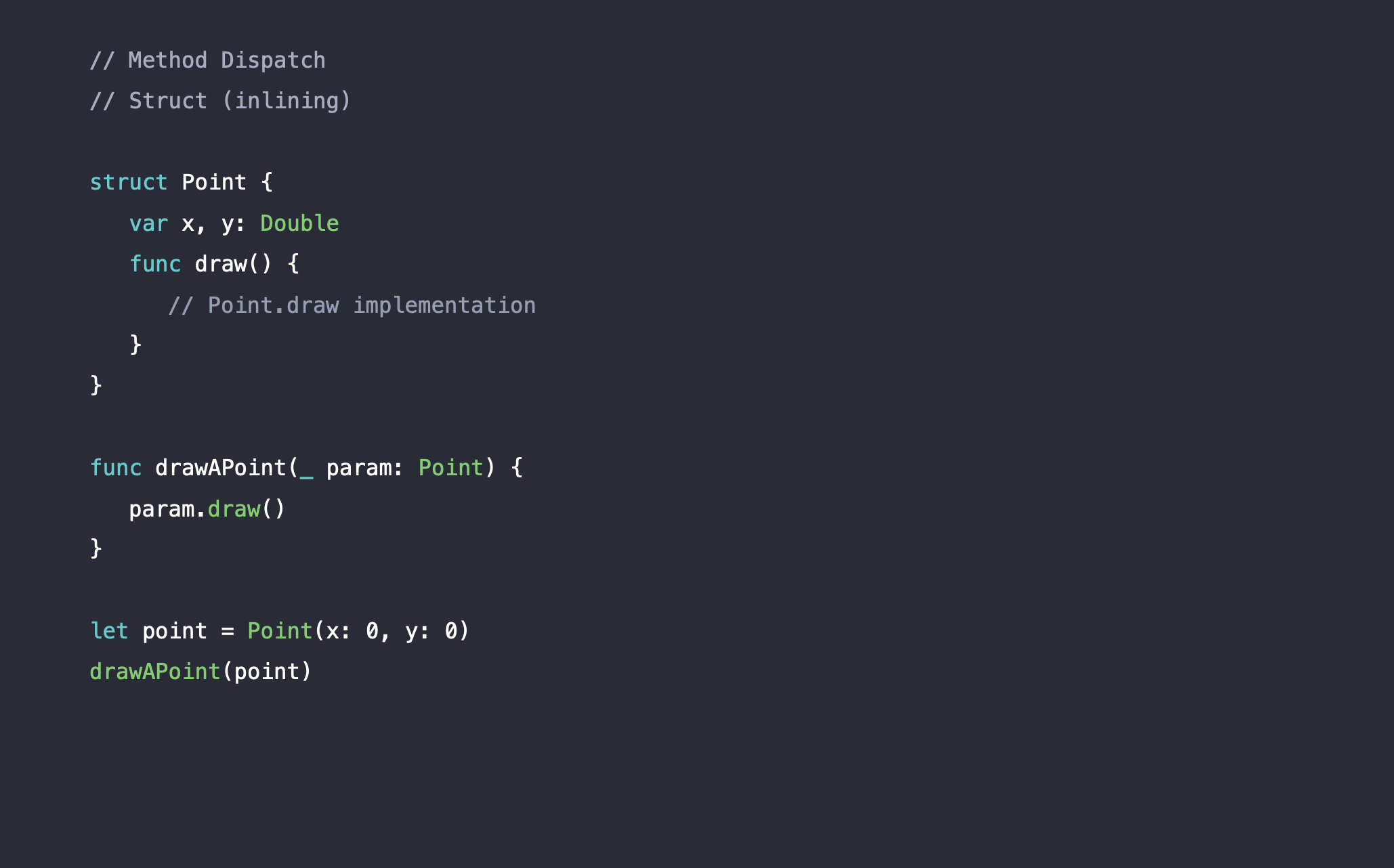
drawAPoint(), point.draw() 이 두개의 메소드 모두 컴파일러가 명확하게 컴파일 시점에 코드를 파악할 수 있습니다. 따라서 static dispatch이며, 컴파일 시점에 두 메소드는 때문에 메소드 인라이닝이 됩니다.
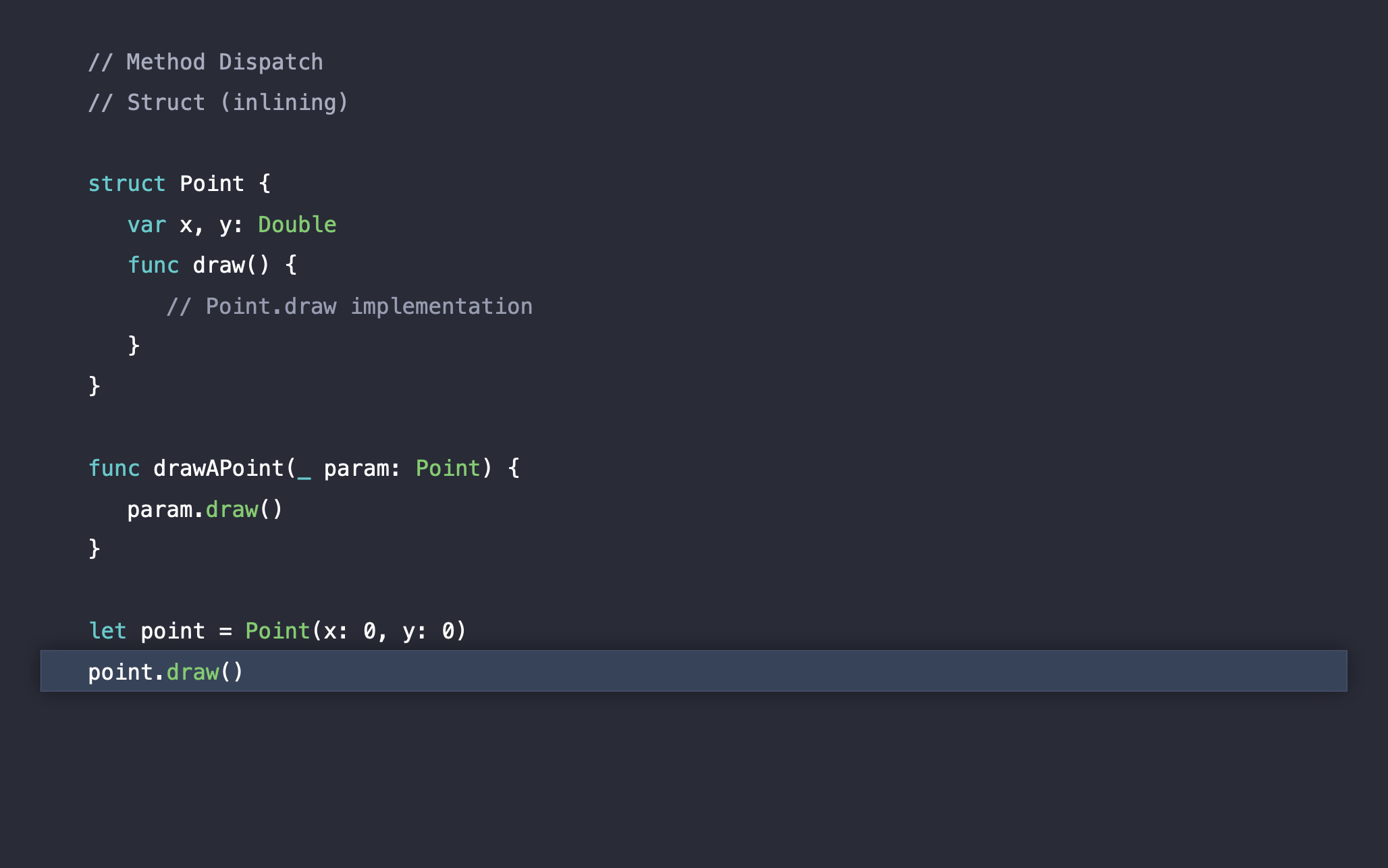
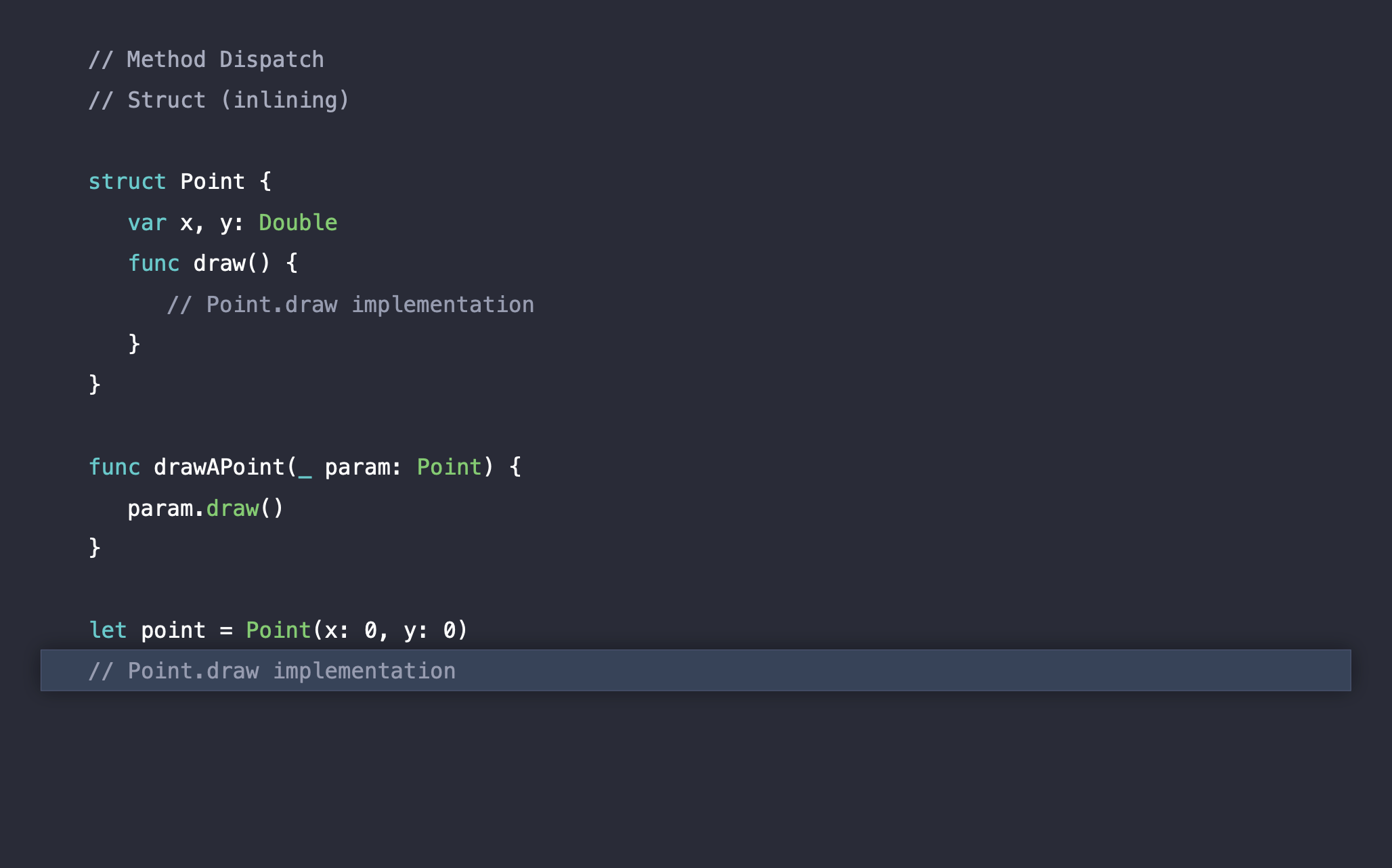
컴파일을 마치고 런타임으로 들어가게 되면, 아래와 같이 실행 후 바로 종료가 됩니다.
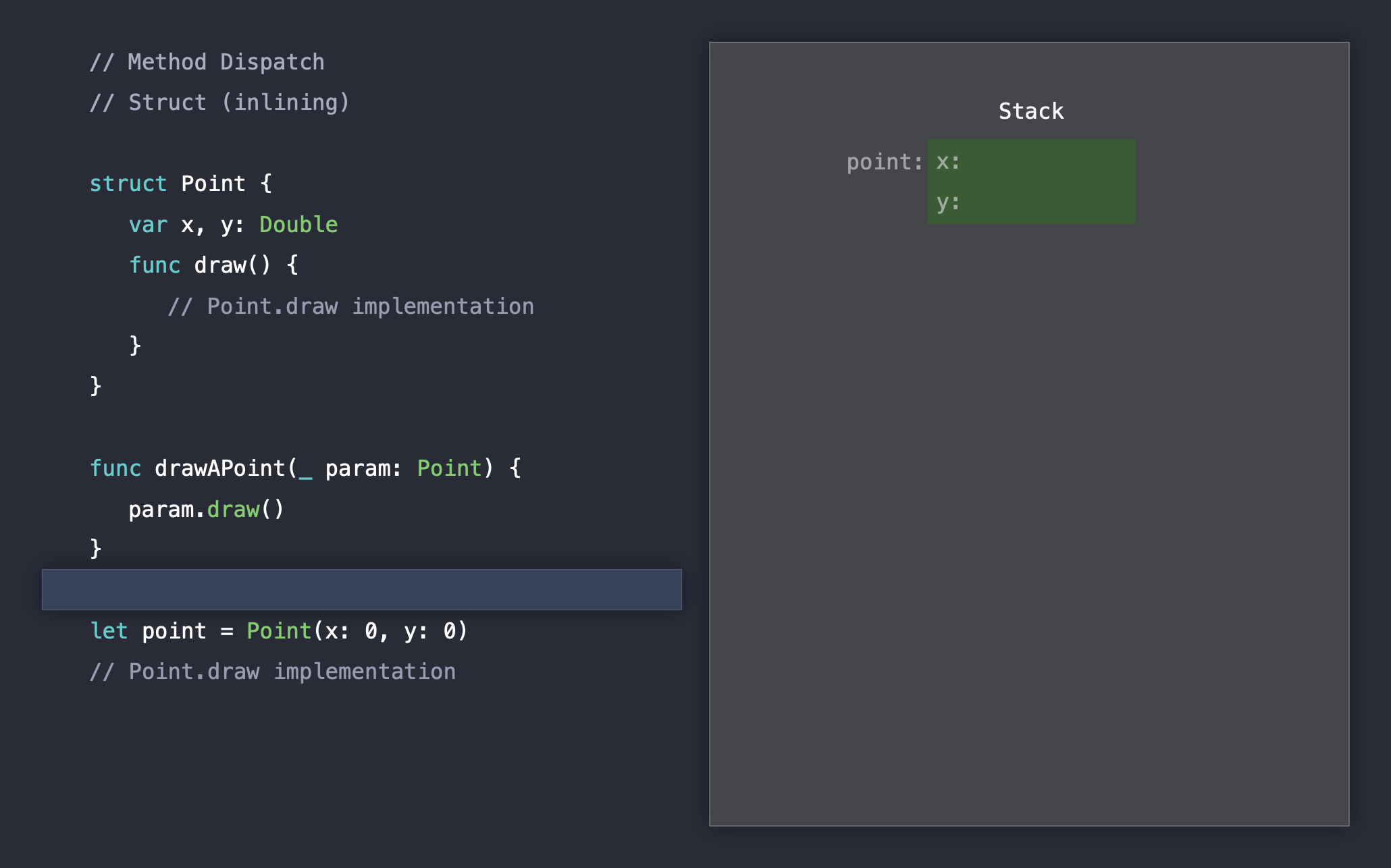
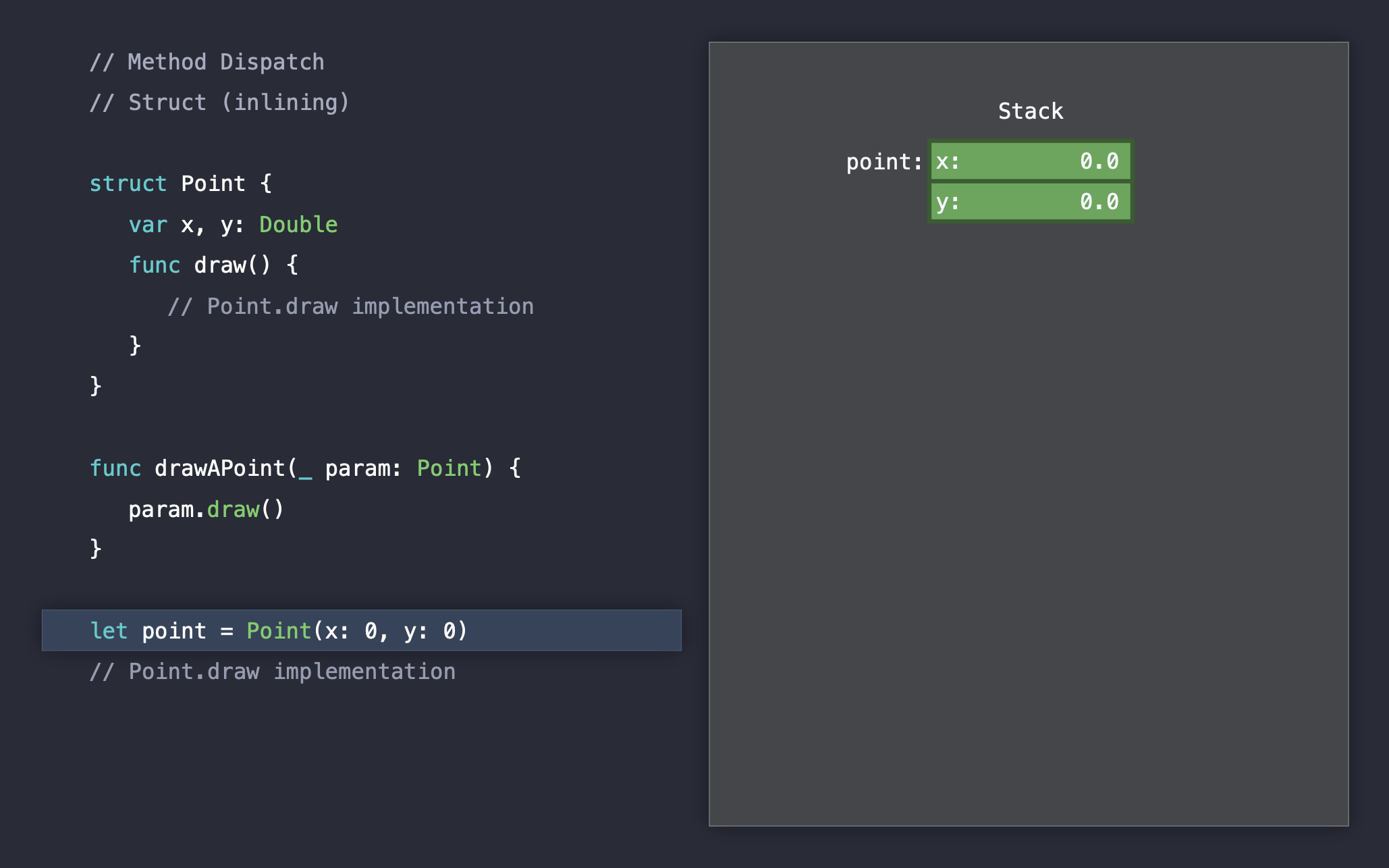
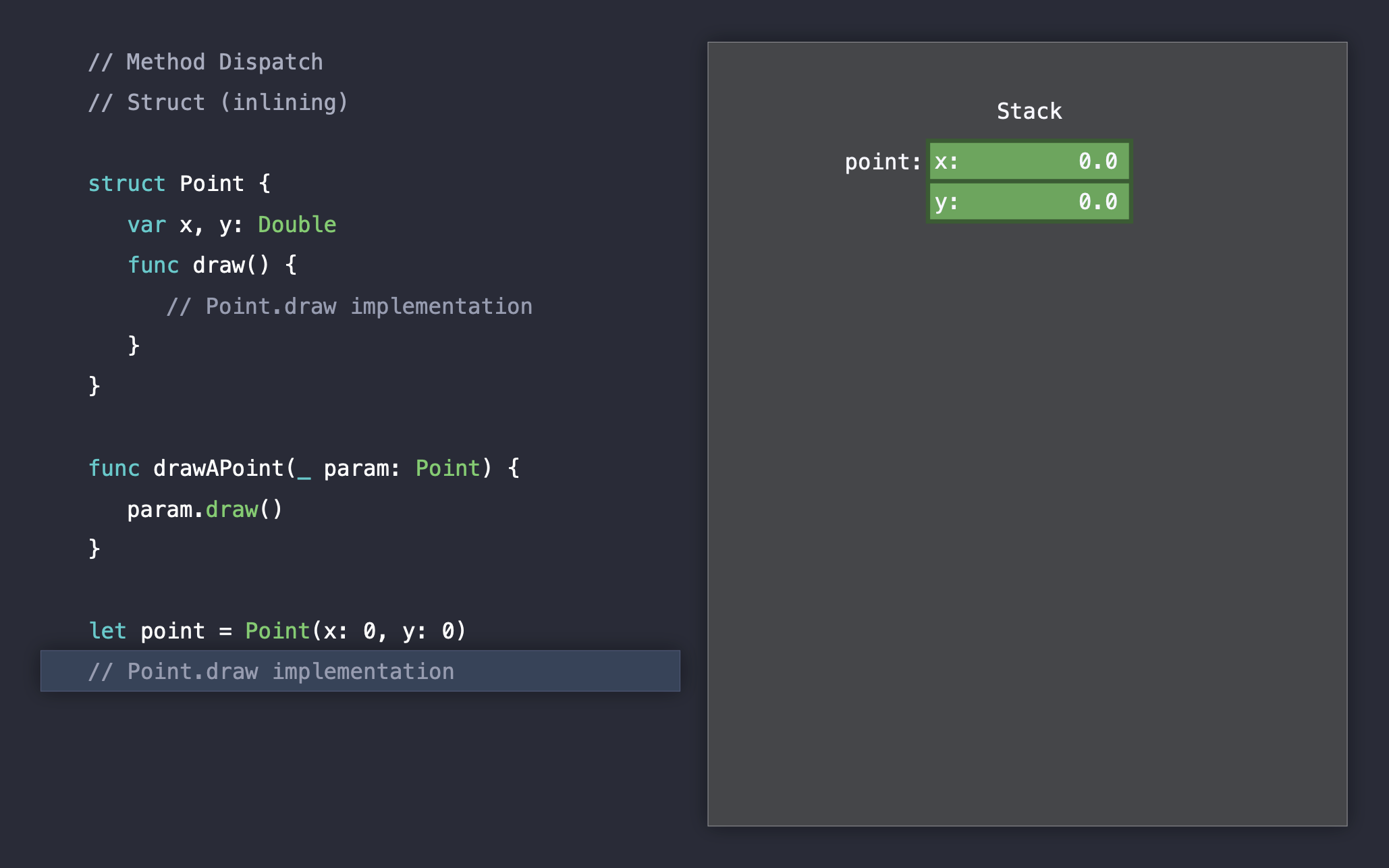
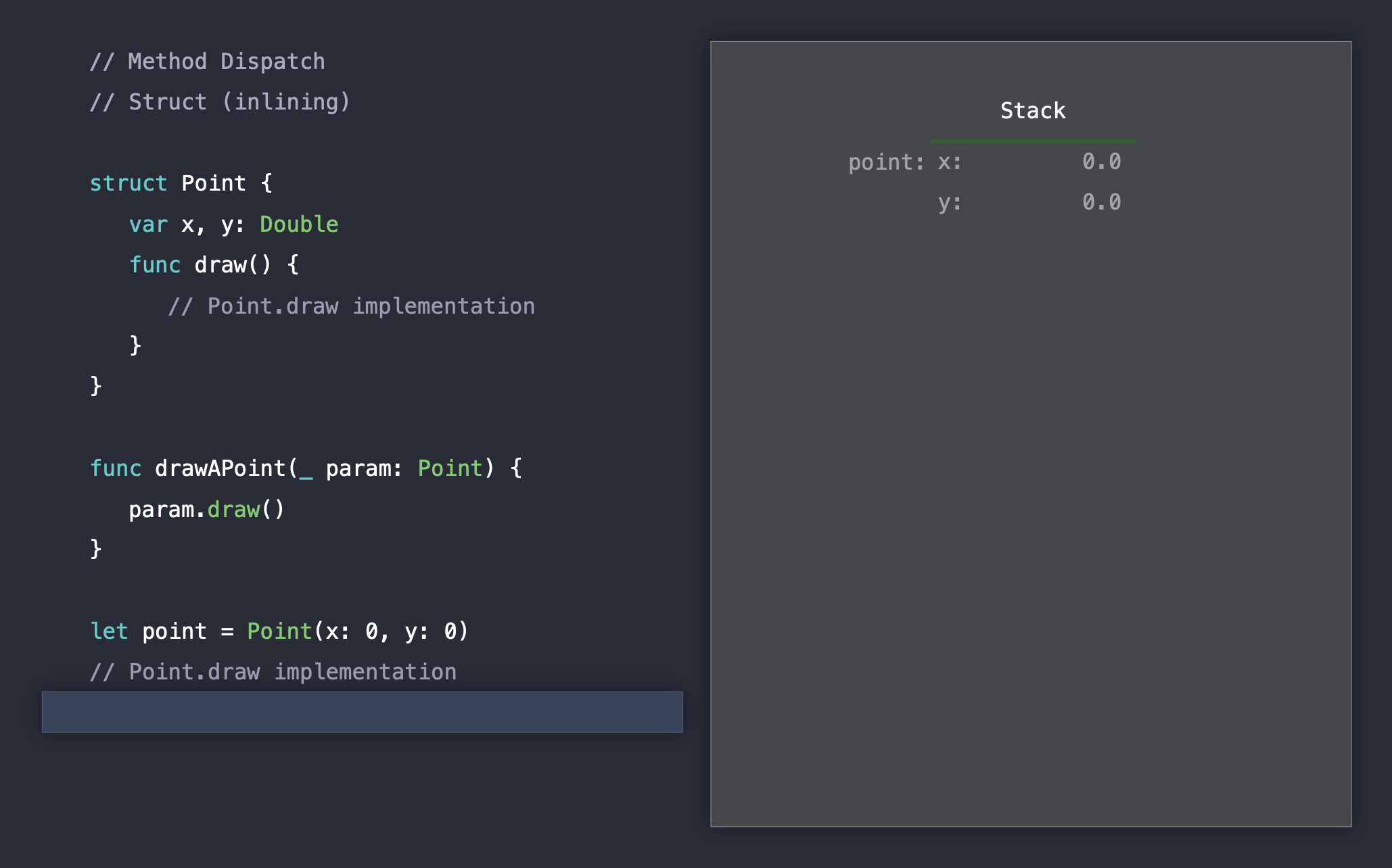
여기서 우리는 두개의 static dispatch을 처리하는 과정에서는 별다른 오버헤드가 발생하지 않는 것을 확인할 수 있습니다. 메소드 인라이닝 덕분에 런타임에는 메소드 호출에서 다른 추가 작업이 필요없기 때문입니다.
단일 static dispatch와 dynamic dispatch의 차이는 크지 않습니다. 하지만 여러개 method dispatch가 발생하는 dispatch chain에서는 차이가 있습니다. Static dispatch chain에서는 컴파일러가 모두 파악할 수 있는 반면에, Dynamic dispatch chain에서는 컴파일러가 추론할 수 없습니다.
컴파일러는 static method dispatch chain을 메소드 인라이닝으로 붕괴시켜서 콜 스택 오버헤드 없이 단일 구현 형태, 즉 하나의 코드 덩어리로 바꿀 수 있습니다. 이를 통해 우리는 static dispatch를 통해 빠른 처리를 할 수 있다는 것을 알 수 있습니다.
Dynamic dispatch in Class
그렇다면 왜 dynamic dispatch가 필요한 것일까요?
가장 큰 이유는 다형성 때문입니다.
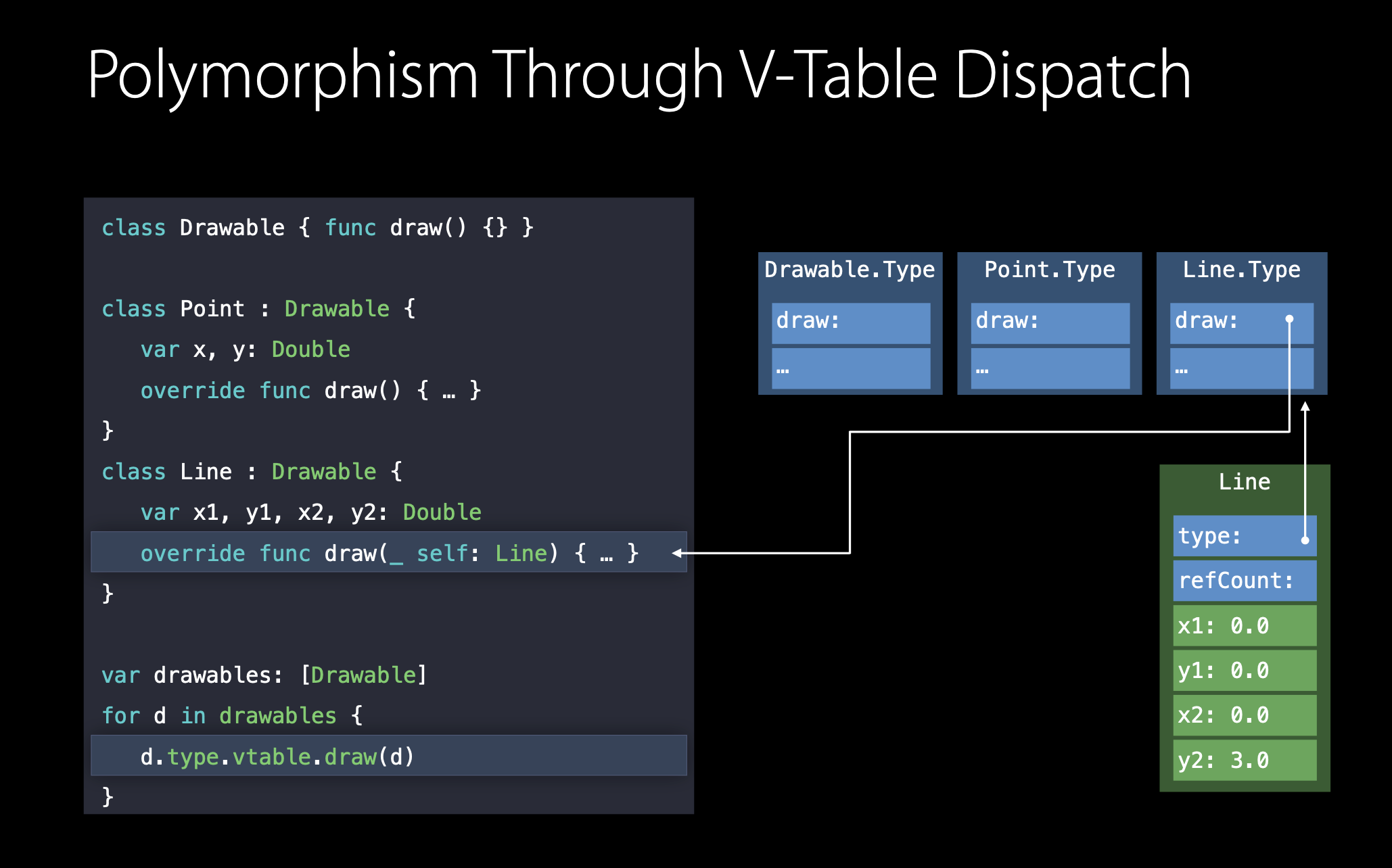
전통적인 객체지향 프로그램의 예시를 살펴보도록 하겠습니다. Drawable은 추상화된 수퍼클래스이며 Point, Line은 Drawable의 서브클래스입니다.
각 서브클래스들은 draw() 함수를 오버라이드하여 각자 구현을 하고 다형성을 따라 drawables라는 Drawable 배열을 생성하였습니다.

Drawable, Point, Line은 모두 클래스이기 때문에 우리는 이들의 배열을 만들게 되면 배열의 각 원소들은 모두 같은 사이즈로 저장이 됩니다. 왜냐하면 우리는 이 친구들을 레퍼런스, 주소값으로 배열에 저장하기 때문입니다.

우리는 for문을 사용하여 배열을 순회하며 draw() 메소드를 호출할 것입니다.
for d in drawables {
d.draw
}
여기서 컴파일러가 컴파일 타임에 draw() 메소드를 정확한 구현 부로 대체할 수 있을까요? Static method dispatch의 메소드 인라이닝과 같이 해당 메소드의 body 구현 부를 대체하는 것은 불가능해 보입니다. d.draw()의 d는 Point가 될 수도, Line이 될 수도 있기 때문입니다.
이를 해결하기 위해서 컴파일러는 클래스에 필드를 하나 더 추가합니다. 이 필드는 클래스의 타입 정보에 대한 포인터이며 타입 정보는 static memory에 저장되어 있습니다.
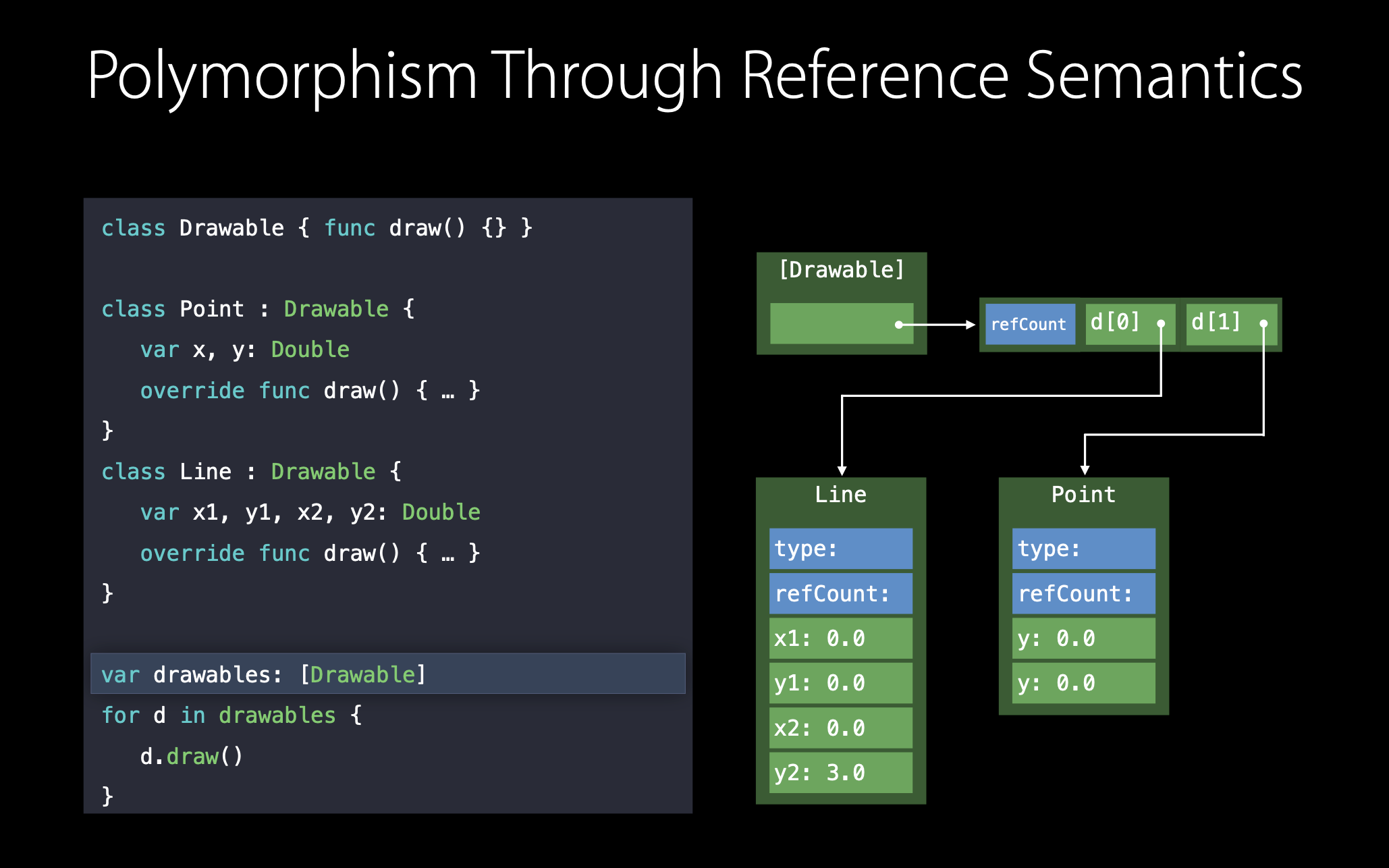
이제 draw 메소드를 호출할 때, 컴파일러는 우리를 대신해 static memory에 있는 타입 정보를 보고 실행되어야 할 구현 부를 가리키는 포인터가 있는 virtial method table를 통해 메소드를 호출합니다. 이 table은 V-Table이라고도 불립니다.

그래서 컴파일러가 어떻게 d.draw()를 타입에 맞게 메소드를 호출하는지 확인해보면 virtual method table을 통해 실행에 올바른 draw() 구현 부를 찾는 것을 볼 수 있습니다.
d.type.vtable.draw(d)
그리고 실제 인스턴스를 암묵적 self-parameter로 넘겨줍니다. 즉, d를 파라미터로 넘겨준 것이죠.
Summary
Class
클래스의 성능은 다음과 같습니다. 클래스는 기본적으로 heap allocation을 사용하고, 이로 인해 reference counting이 발생하게 됩니다. 또한 dynamic dispatch로 메소드를 호출합니다. 하나의 메소드만 봤을 때, Dynamic dispatch는 static dispatch와 큰 차이는 없지만, 메소드 체인과 같은 여러 메소드가 얽혀있는 상황에서는 메소드 인라이닝과 같은 최적화를 할 수 없습니다.

final Class
서브클래스를 만들지 않을 클래스라면, final을 클래스 앞에 선언하여 컴파일러가 static하게 dispatch하게 할 수 있습니다. 또한 팀원들에게도 서브클래스 하지 않을 의도를 보여줄 수 있습니다.

Struct
Struct의 성능은 다음과 같습니다.

마치며
여기까지 스위프트의 성능에 영향을 주는 것을 3가지, allocation, reference couting, method dispatch를 살펴보았습니다. 이제 코드를 작성하거나 리뷰할 때, 이 세가지를 고려해보면 좋을 것 같습니다.
Apple에서 왜 struct를 사용하라고 권장하는지도 조금 더 이해가 되는 것 같습니다. 하지만 struct의 성능이 좋다고 해서 무조건 struct를 사용하는것은 바람직하지 않다고 생각이 듭니다. 또한 class를 사용할 수 밖에 없는 상황도 많이 있기 때문이죠. 아직 해당 WWDC 발표의 모든 부분을 정리한게 아니기 때문에 남은 부분을 추후에 정리해서 포스팅할 예정입니다. 읽어주셔서 감사합니다! 😁
도움 주신 고마운 분들 🌼
- Olaf
- Gangwoon


댓글남기기